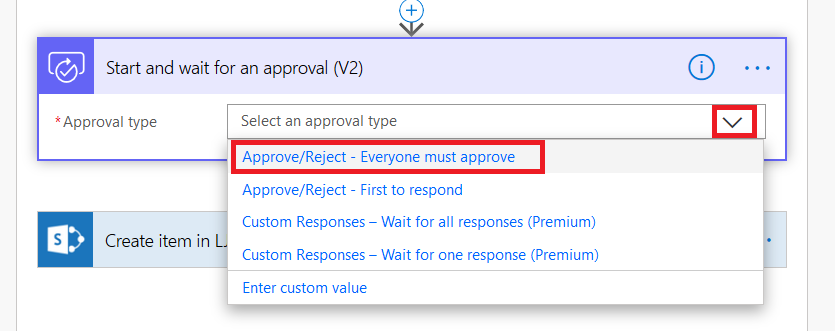
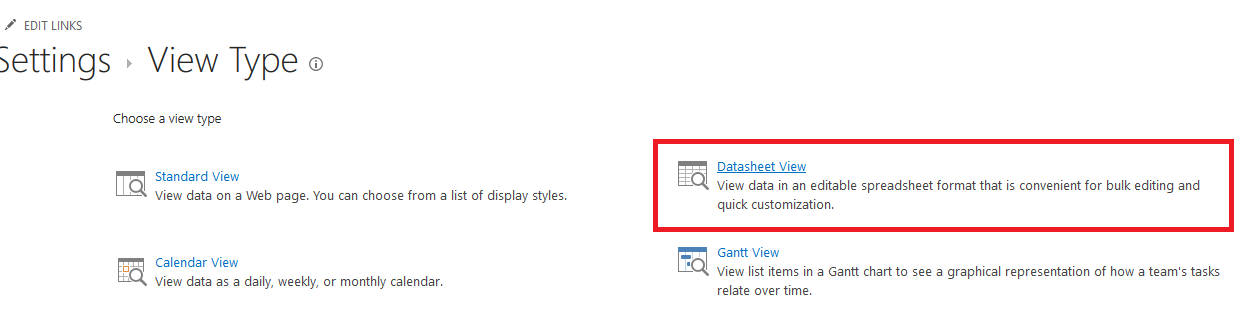
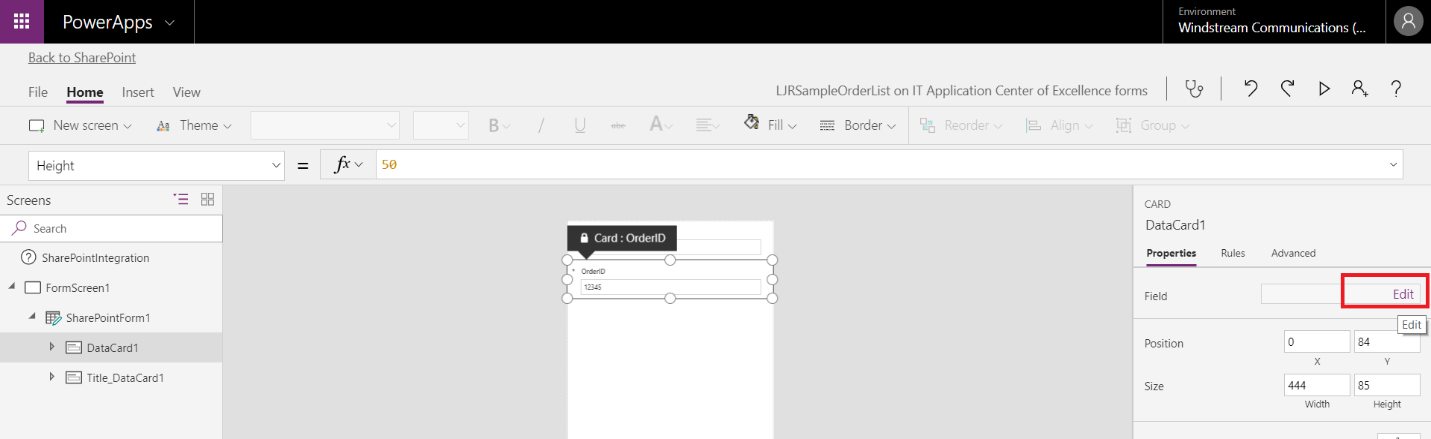
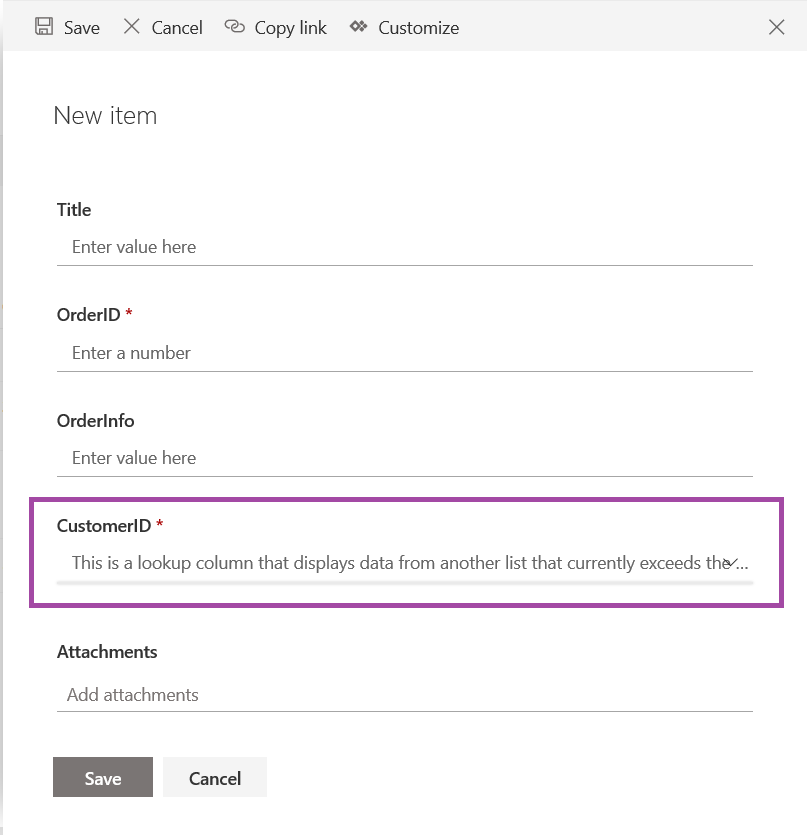
Not crud like “ugg, that’s a bunch of crud … let’s load it up in a SharePoint list to store it forever!” – that wouldn’t make sense at all. In programming-speak, CRUD is an abbreviation for Create, Update, Read, Delete – the basic types of operations for data storage. And you can create, update, read, and delete SharePoint list items through the REST API.
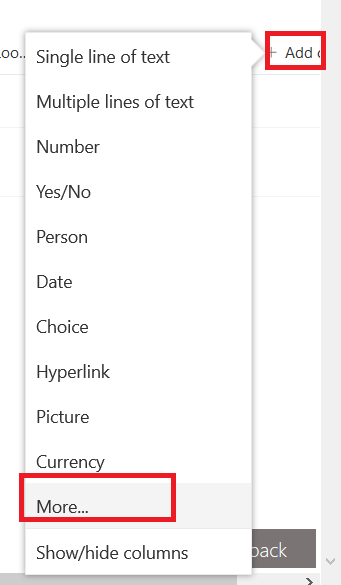
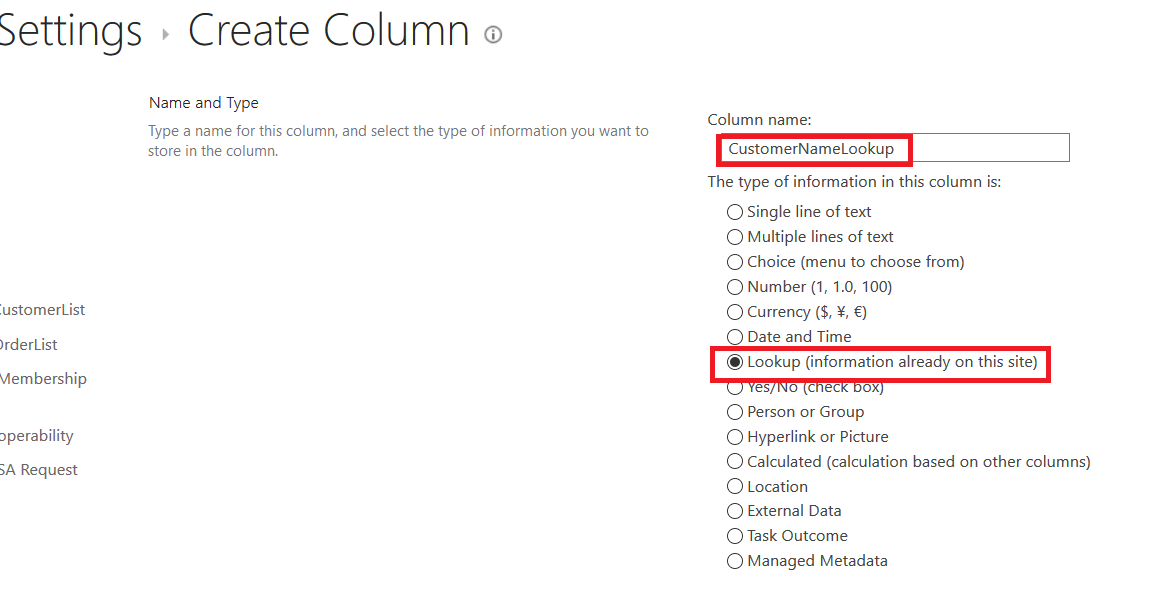
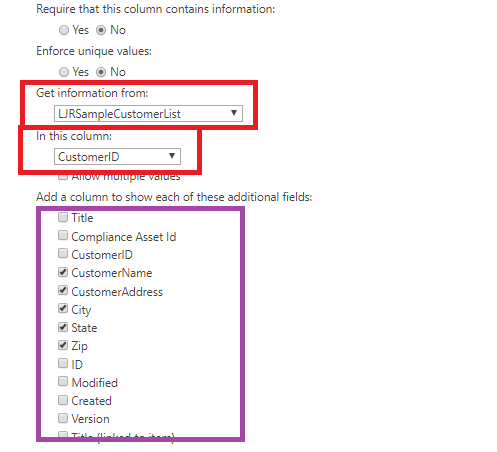
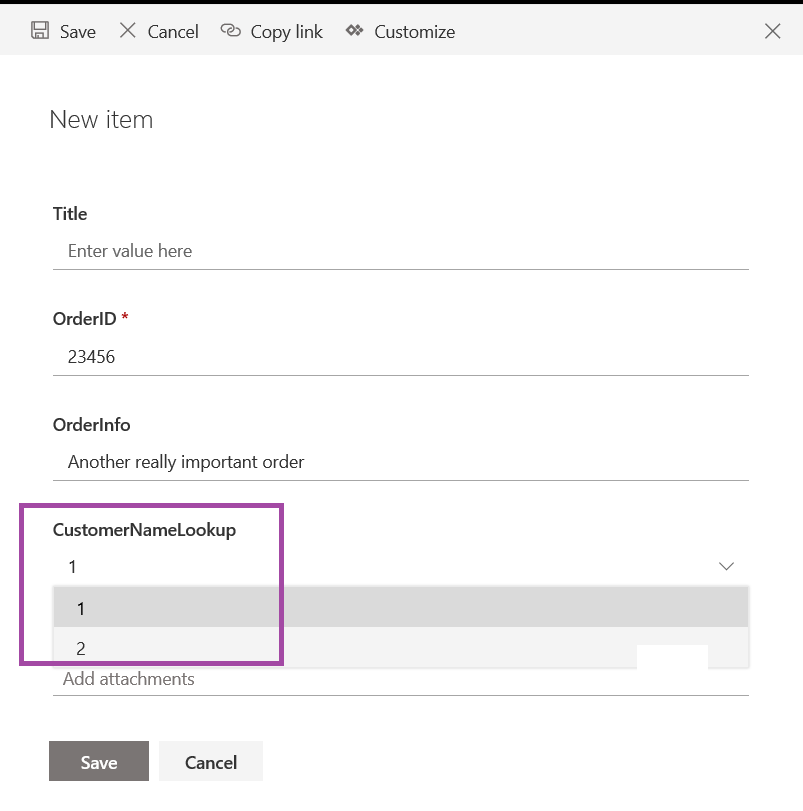
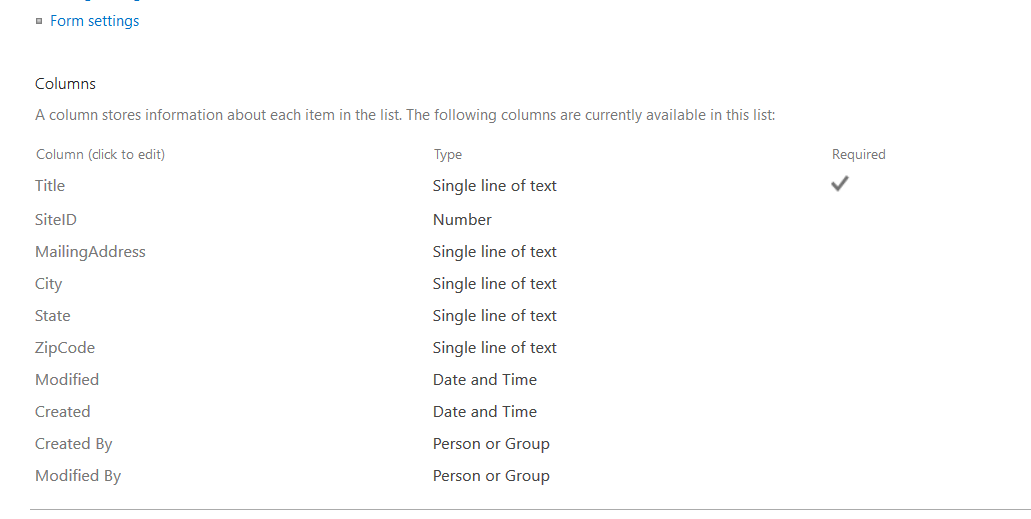
First, you’ll need a list. Here, I am using a sample list that has columns for SiteID, MailingAddress, City, State, and ZipCode – the usual information if you’re going to use a LOOKUP column to correlate a location in a record with address details for the location (i.e. there’s no reason to type 1925 Enterprise Parkway and such in every order you want to ship to the Twinsburg office).
And you need some sort of code that communicates with the REST API – something that sends HTTPS calls. In the example code, I am using Python. Functions, along with example code to use those functions can be found at https://github.com/ljr55555/spoRestAPICRUD. Clone the repository locally.
You will find a config.sample – I use this as a template for storing user-specific configuration parameters. Copy config.sample to config.py and edit config.py. The actual config.py is included in the .gitignore file, so retrieving updates from the repository won’t wipe our your settings.
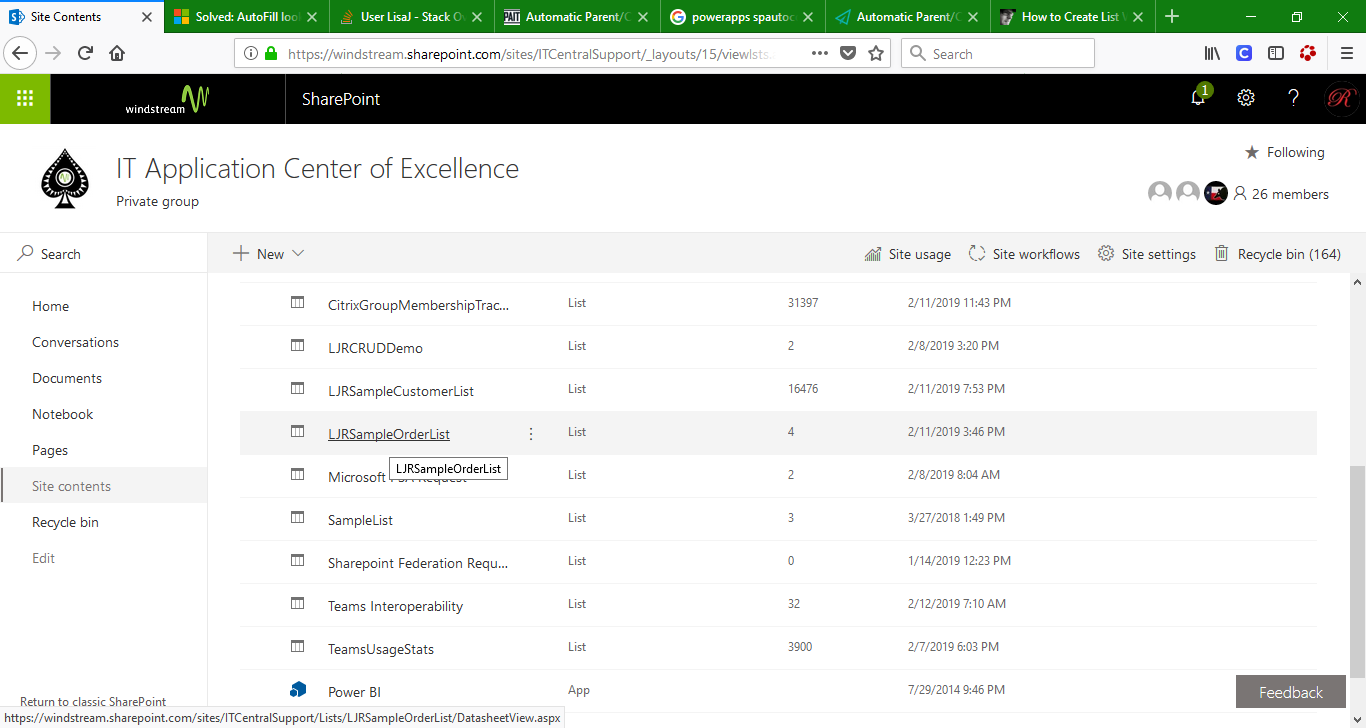
There are a handful of values you will need to set. Most of the values you can get from your list’s web address. Open your list in the web browser of your choice and find the information in the address line:
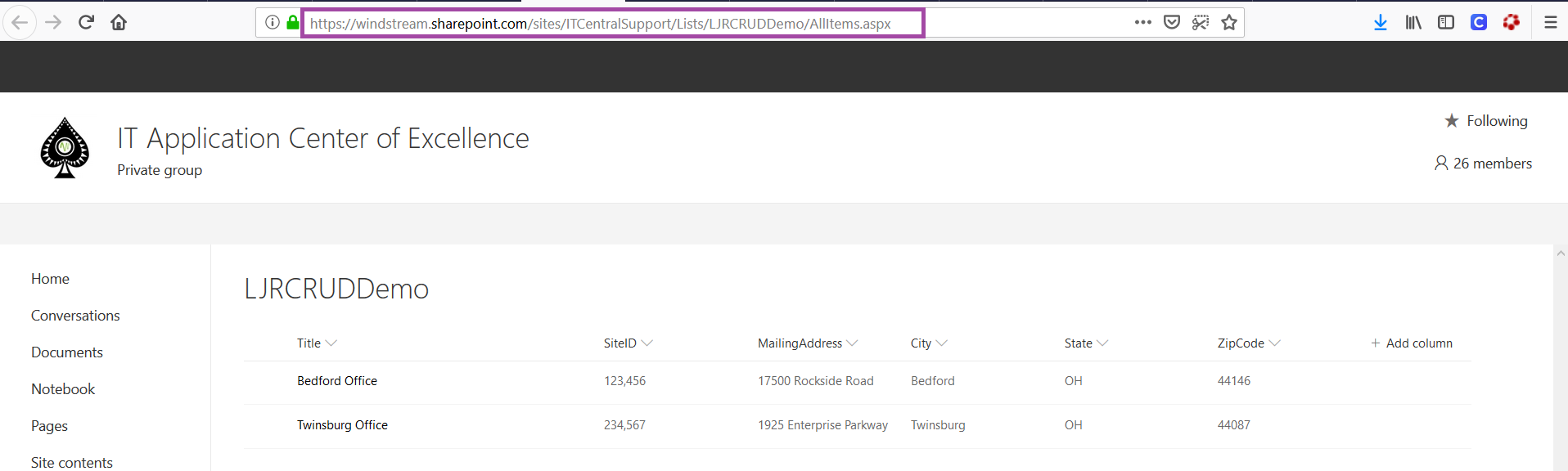
There are three values we need to extract from this URL – the SharePoint tenant address, your SharePoint site name, and the list name

Edit config.py and modify the following variables with your list-specific information
strConnectURL = “tenant.sharepoint.com”
strContextURI = “https://tenant.sharepoint.com/sites/SiteName/_api/contextinfo”
strListInfoURI = “https://tenant.sharepoint.com/sites/SiteName/_api/web/lists/GetByTitle(‘ListName‘)”
Then you need some credentials – this config file will need to be updated when the account password changes, so you may wish to use a non-user account with a very long password that changes less often.
Obviously, typing a username and password in clear text is a bad idea. I’m using simplecrypt to keep an encrypted password in the config file which is decrypted using a key in the script file. Anyone who obtains both files can decrypt the password – in my production code, the key comes from another location to reduce the probability of someone accessing the key file.
Use stashStringForConfig.py to generate the string to use for the username and password values – change strKey to match whatever you are using for your key, and change strString to your user id. Run the script and copy the output into your config.py file. Change strString to your password and repeat the process.
C:\ljr\git\spoRestAPICRUD>python stashStringForConfig.py
b’c2MAAnHWW1nqXuc4bO+pt8q1FjTG6Q5CYNz1O5ORHnJxl8vBOpGKj0HxVSYdGa1o+Ij/VicrQLTWTyU7P0StspMEJ7zBe/qtFWuHGrfEvnLO5dU=’
That’s it for configuration – at this point, if you have a list with the same columns I do, you can run the script.
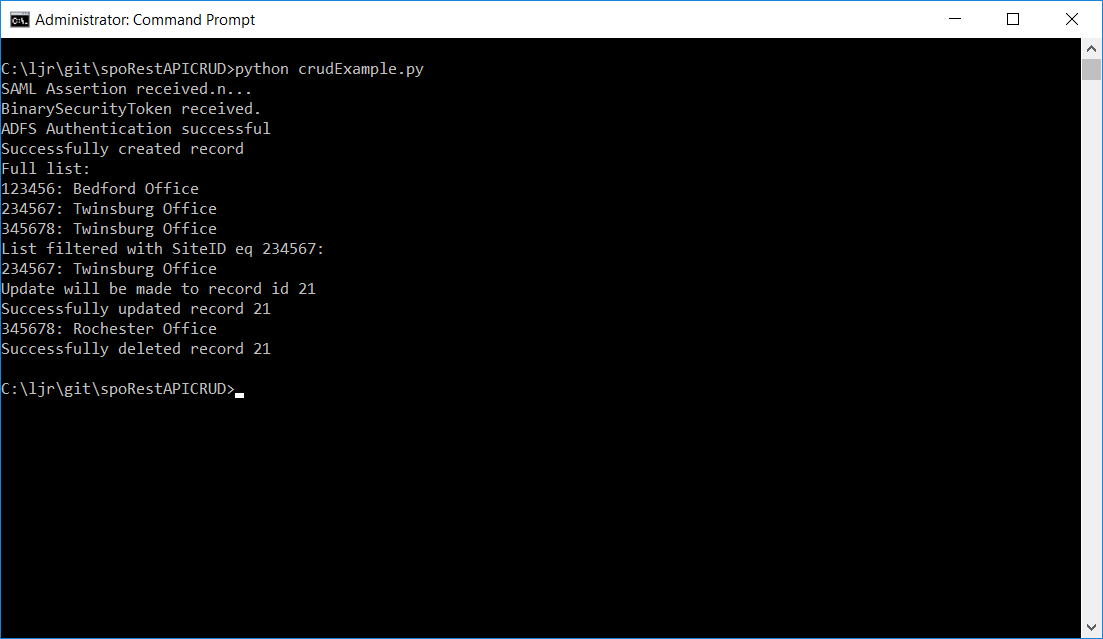
Voila, records!

What’s the script doing? Well – CRUD, of course!
Connecting To SharePoint Online – I am using a modified version of sharepy which can be found in the develop branch of my fork of the repository. This is a requests wrapper that handles authentication to SharePoint Online. The connection, in my script, is named spoConnection. The arguments supplied are sourced from config.py
spoConnection = sharepy.connect(strConnectURI,strUID,strPass)
Creation – You need a dictionary with your data. The required metadata type value is retrieved from your list. The remaining key:value pairs in the dictionary are the column names and record values, respectively.
{“__metadata”: { “type”: strListItemEntityTypeFullName}, “Title”: “Bedford Office”, “SiteID”: ‘123456’, “MailingAddress”: “17500 Rockside Road”, “City”: “Bedford”, “State”: “OH”, “ZipCode”: “44146”}
The writeNewRecord function will insert the record into your list. The dictionary containing my record is called strBody (because it ends up being the HTTP POST body).
iNewRecordResult = writeNewRecord(spoConnection, strContextURI, strListDataURI, strBody)
Read – Now that we have records, we can retrieve the full list or filter to find specific records. To find all records, run findSPRecord – the arguments are the SharePoint connection and the URI for the list.
jsonResult = findSPRecord(spoConnection, strListDataURI)
If you want to return a filtered subset of data, add the column on which to filter, the filter operator, and the value. You can construct more complex ODATA filters – see the ODATA query operations supported in the SharePoint REST API for more information.
jsonResult = findSPRecord(spoConnection, strListDataURI, “SiteID”, “eq”, “234567”)
Update – I intentionally included incorrect data in one of my create lines – the Twinsburg office isn’t in Rochester NY! To update a record, you need it’s internal ID number. The findSPRecordID function has the same parameters as findSPRecord, but instead of returning the full record, it returns the integer record ID.
iRecordToUpdate = findSPRecordID(spoConnection, strListDataURI, “SiteID”, “eq”, “345678”)
Now that we have a record number, we also need a dictionary with the new values. Values that are not changing do not need to be included – just anything value you want to update. As with the record creation, the metadata type is determined programmatically.
dictRecordPatch = {“__metadata”: { “type”: strListItemEntityTypeFullName}, ‘Title’: “Rochester Office”}
And then updateRecord is called to write the new information into the selected record.
iRecordPatchResult = updateRecord(spoConnection, strContextURI, strListDataURI, dictRecordPatch)
Delete – Delete operations are similar to update operations – you need to find the internal record ID number to delete it. There’s no validation – nothing checks that the City for item #x is Rochester.
iDeletionResult = deleteRecord(spoConnection, strContextURI, strListDataURI, iRecordToDelete)
By combining CRUD operations, you can use a SharePoint list as a user-created and user-administered database. SharePoint still stores its information in a Microsoft SQL database, and going through the REST API to interact with your data adds overhead … so this isn’t a good approach for someone with an enormous data set where views would speed up data access or complex join operations are warranted. But for someone with fairly straight-forward database requirements, you may be able to do-it-yourself using SharePoint lists.