You can use a pre-built docker container (the “long term support” iteration is published as jenkins/jenkins:lts) or perform a local installation from https://jenkins.io/download/, add a package repo to your package manager config (http://pkg.jenkins-ci.org/redhat-stable/jenkins.repo for RedHat-based systems), or build it from the source repo. In this sandbox example, I will be using a Docker container.
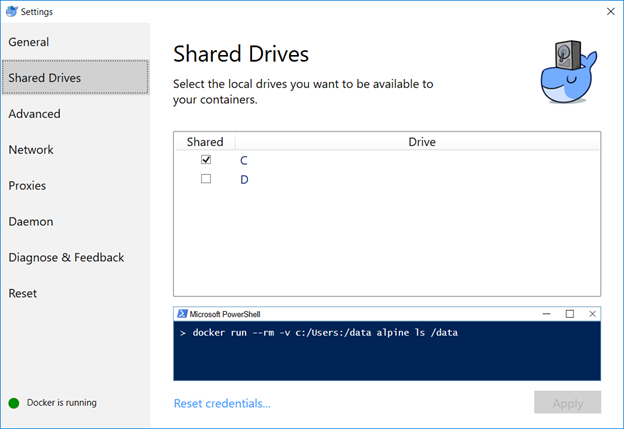
Map the /var/Jenkins_home value to something. This allows you to store user-specific data on your local drive, not within the Docker image. In my case, c: is shared in Docker and I’m using c:\docker\jenkins\jenkins_home to store the data.
I have a java cacerts file mounted to the container as well – my CA chain has been imported into this file, and the default password, changeit, is used. This will allow Java to trust internally signed certificates. The keystore password appears as part of the process (i.e. anyone who can run commands like “ps aux” or “ps -efww” will see this value, so while security best practices dictate the default password should be changed … don’t change it to something like your root password!).
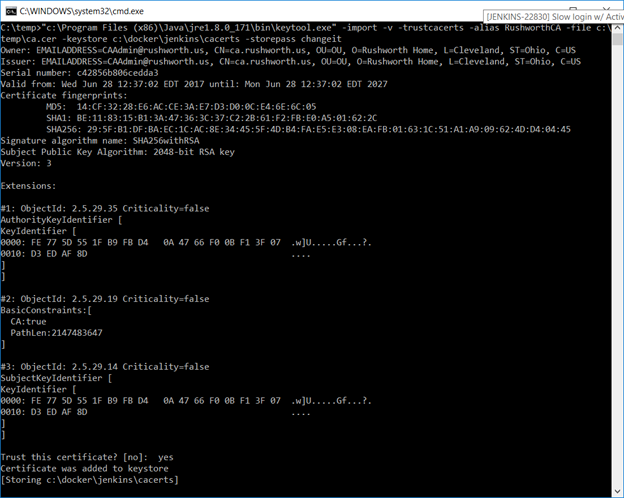
We can now start the Docker container:
docker run -p 8080:8080 -p 50000:50000 -v /c/docker/jenkins/jenkins_home:/var/jenkins_home -v /c/docker/jenkins/cacerts:/usr/lib/jvm/java-8-openjdk-amd64/jre/lib/security/cacerts jenkins/jenkins:lts
Once the container is running, you can visit the management web site (http://localhost:8080) and install the modules you want – or just take the defaults (you’ll end up with ‘stuff’ you don’t need … I don’t use subversion, for instance, and don’t really need a plugin for it). For a sandbox, I accept the defaults and then use Jenkins => Manage Jenkins => Manage Plug-ins to remove obviously unnecessary ones. And add any that may be needed (e.g. if you are using Visual Studio solution files, add in the MSBuild plugin).
Configuring Authentication (LDAP)
First install the appropriate plug-in – referrals cause authentication problems when using AD as the LDAP authentication source, if you are using AD for authentication … use the Active Directory plugin).
Manage Jenkins => Configure Global Security. Under access control, select the radio button for “LDAP” or “Active Directory”. Configuration is implementation specific.
AD:
Click the button to expand the advanced configuration. You should not need to specify a domain controller if service records for the domain are present in DNS. The “Site” should be “UserAuth”. For the Bind DN, you can use your userid (user@domain.ccTLD or domain\uid format) with your password. Or you can create a dedicated service account – for a “real world” implementation, you would want a dedicated service account (using *your* account means you’ll need to update your Jenkins config whenever you change your password … and when you forget this update, auth fails).
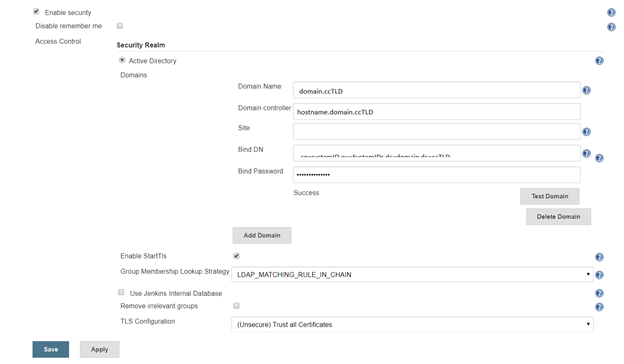
A note about the group membership lookup strategy:
For some reason, Jenkins assumes recursive group memberships will be used (e.g. there is a “App XYZ DevOps Team” that is placed into the “Jenkins Users” group, and “Jenkins Users” is assigned authorizations within the system). Bit of a shame that “none” isn’t an option for cases where there isn’t hierarchical group membership being built out.
There are three lookup strategies available: recursive group queries, LDAP_MATCHING_RULE_IN_CHAIN, and Toke-Groups user attribute. There have been bugs in the “Automatic” strategy that caused timeout failures. Additionally, the group list returned by the three strategies is not identical … so it is possible to have inconsistent authorization results as different strategies are used. To ensure consistent behaviour, I select a specific strategy.
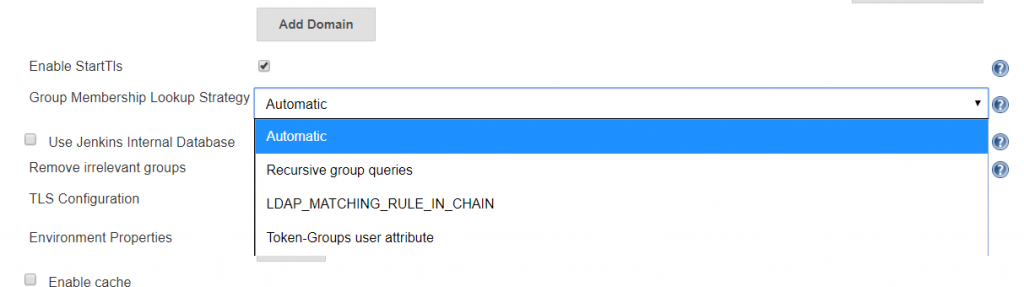
Token-Groups: If you are not using Distribution groups within Jenkins to assign authorization (and you probably shouldn’t since it’s a distribution group, not a security group), you can select the Token-groups user attribute to handle recursive group membership. Token-groups won’t work if you are using distribution groups within Jenkins, though, as only security groups show up in the token-groups attribute.
LDAP_MATCHING_RULE_IN_CHAIN: OID 1.2.840.113556.1.4.1941, LDAP_MATCHING_GROUP_IN_CHAIN is an extended matching operator (something Microsoft added back in Windows 2003 R2) that can be used in LDAP filters:
(member:1.2.840.113556.1.4.1941:=cn=Bob,ou=ResourceUsers,dc=domain,dc=ccTLD)
This operator has known issues with high fan-outs and can cause hangs while data is retrieved. It is, however, a more efficient way of handling recursive group memberships. If your Jenkins groups contain only users, you will not encounter the known issue. If you are using nested groups, my personal recommendation would be to test each option and time logon activities … but if you do not wish to perform a test, this is a good starting option.
Recursive Group Queries: Jenkins issues a new LDAP query for each group – a lot of queries, but straight-forward queries. This is my last choice – i.e. if everything else hangs and causes poor user experience, try this selection.
For Active Directory domains that experience slow authentication through the AD plug-in regardless of the selected recursion scheme, I’ve set up the LDAP plug-in (it does not handle recursive group memberships) but it’s not a straight-forward configuration.
LDAP:
Click the button to expand the advanced server configuration. Enter the LDAP directory connection details. I usually start with clear text LDAP. Once the clear text connection tests successfully, the certificate trust can be established.
You can add a group search filter, but this is not required. If you request your group names start with a specific string, e.g. my ITSS CSG organization’s Jenkins server might use groups that start with ITSS-CSG-Jenkins, you can add a cn filter here to restrict the number of groups your implementation looks through to determine authorization. My filter, for example, is cn=ITSS-CSG-Jenkins*
Once everything is working with clear text, load the Root and Web CA public keys into your Java instance’s cacerts file (if you have more than once instance of Java and don’t know which one is being used … either figure out which one is actually being used or repeat the keytool commands for each cacerts file on your machine).
In the Docker container, the file is /usr/lib/jvm/java-8-openjdk-amd64/jre/lib/security/cacerts and I’ve mapped in from a locally maintained cacerts file that already contains our public keys for our CA chain.
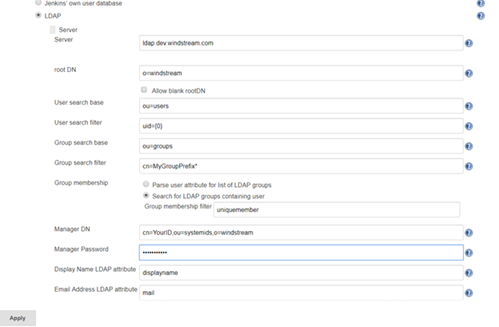
Before saving your changes, make sure you TEST the connection.
Under Authorization, you can add any of your AD/LDAP groups and assign them rights (make sure your local back door account has full rights too!).
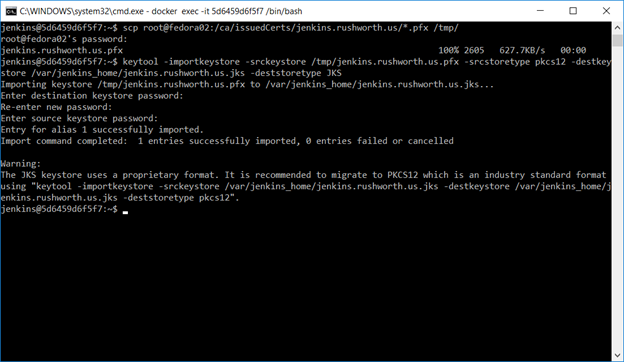
Finally, we want to set up an SSL web site. Request a certificate for your server’s hostname (make sure to include a SAN if you don’t want Chrome to call your cert invalid). Shell into the Docker instance, cd into $JENKINS_HOME, and scp the certificate pfx file.
Use the keytool command to create a JKS file from this PFX file – make sure the certificate (PFX) and keystore (JKS) passwords are the same.
Now remove the container we created earlier. Don’t delete the local files, just “docker rm <containerid>” and create It again
docker run –name jenkins -p 8443:8443 -p 50000:50000 -v /c/docker/jenkins/jenkins_home:/var/jenkins_home -v /c/docker/jenkins/cacerts:/usr/lib/jvm/java-8-openjdk-amd64/jre/lib/security/cacerts jenkins/jenkins:lts –httpPort=-1 –httpsPort=8443 –httpsKeyStore=/var/jenkins_home/jenkins.cert.file.jks –httpsKeyStorePassword=keystorepassword
Voila, you can access your server using an HTTPS URL. If you review the Jenkins documentation, they prefer leaving the Jenkins web server on http and using something like a reverse proxy to perform SSL offloading. This is reasonable in a production environment, but for a sandbox … there’s no need to bring up a sandbox Apache server just to configure a reverse proxy. Since we’re connecting our instance to the real user passwords, sending passwords around in clear text isn’t a good idea either. If only you will be accessing your sandbox (i.e. http://localhost) then there’s no need to perform this additional step. The server traffic to the LDAP / AD directory for authentication is encrypted. This encryption is just for the client communication with the web server.
Using Jenkins – System Admin Stuff
There are several of “hidden” URLs that can be used to control the Jenkins service (LMGTFY, basically). When testing and playing with config parameters, restarting the service was a frequent operation, so I’ve included two service restart URLs here:
https://jenkins.example.com:8443/safeRestart ==> enter quiet mode, wait for running builds to complete, then restart
https://jenkins.example.com:8443/restart ==> Restart not so cleanly
Multiple discussions about creating a more fault tolerant authentication scheme within Jenkins exist on their ‘Issues’ site. Currently, you cannot use local accounts if the directory service is unavailable. Not a big deal if you’re on the company network and using one of our highly available directory solutions. Bit of a shocker, though, if your sandbox environment is on your laptop and you try to play with the instance when not on the company network. In production implementations, this would be a DR consideration (dependency on the directory being recovered). In a cloud-hosted implementation, this creates a dependency on network connectivity into the company.
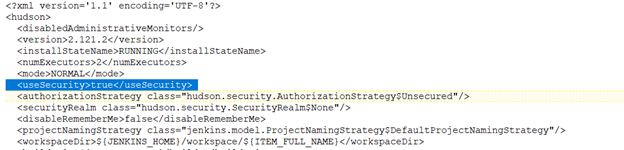
As an emergency solution, you can disable security on your Jenkins installation. I’d also get some sort of firewall rule (OS-based or hardware firewall) to restrict console access to a trusted terminal server or workstation. To disable security, stop Jenkins. Edit the config.xml file in $JENKINS_HOME, and ifnd the <useSecurity> section. Change ‘true’ to ‘false’ and start Jenkins. You’ll be able to access the console without credentials.
Updating Jenkins Image
General practice for updating an application is not to update a container. Instead, download an updated image and recreate the container with the new image. I store the container initialization command along with the folder to which image directories are mapped. My file system has /path/to/docker/storage/AppName that contains a text file with the initialization command and folder(s) that are mapped into the container. This avoids having to find the proper initialization parameters when I upgrade the container.
To update the container, pull a new image, stop the container, remove the container, and create it again. That is:
docker stop jenkins
docker pull jenkins/jenkins:lts
docker rm jenkins
<whatever you used to create the container>