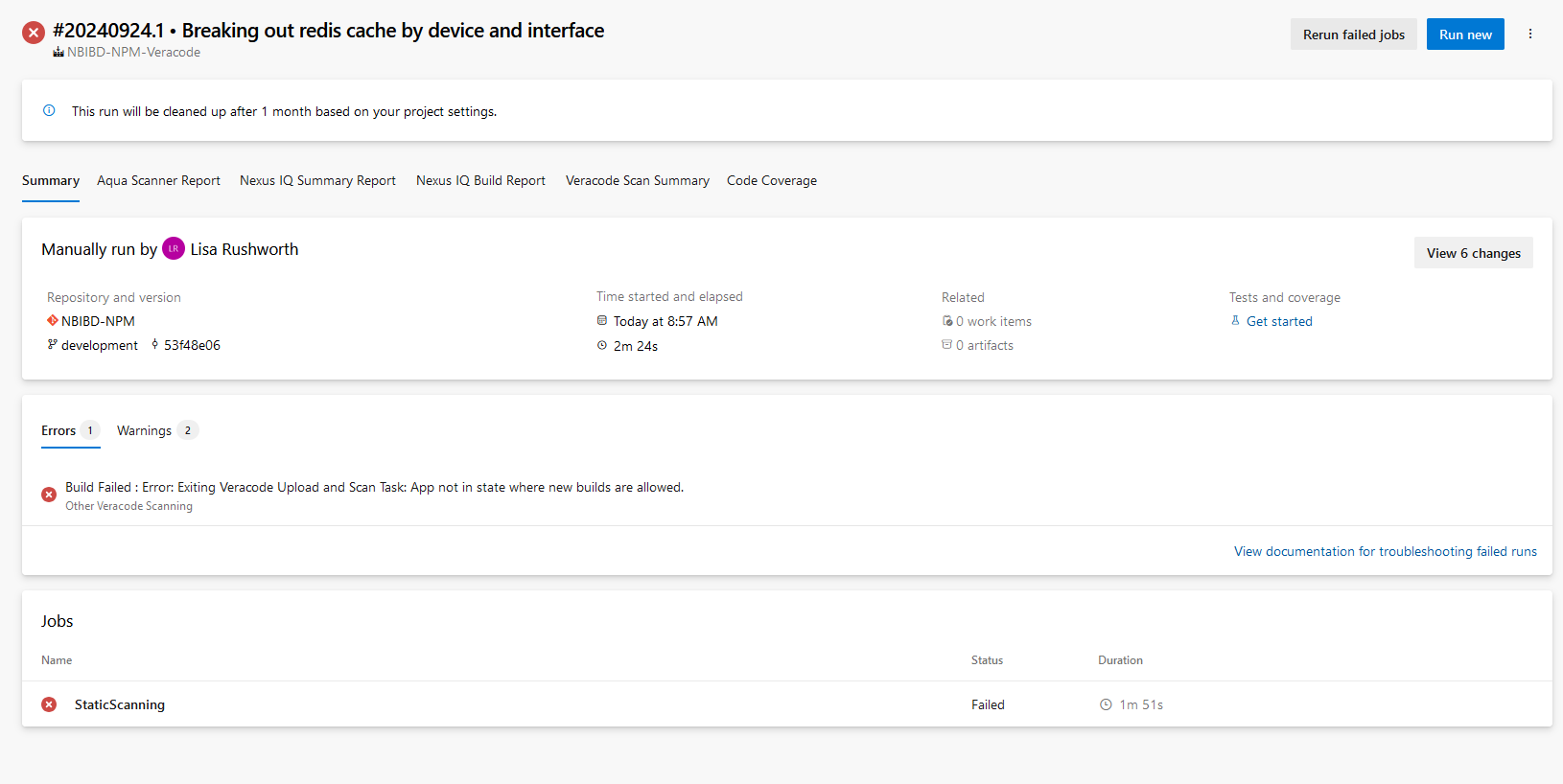
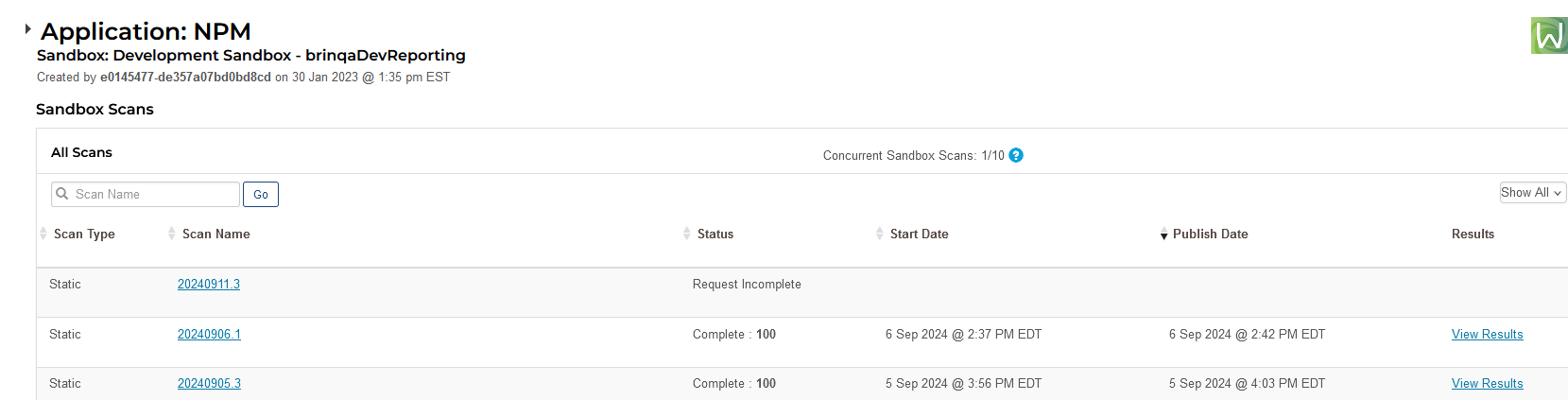
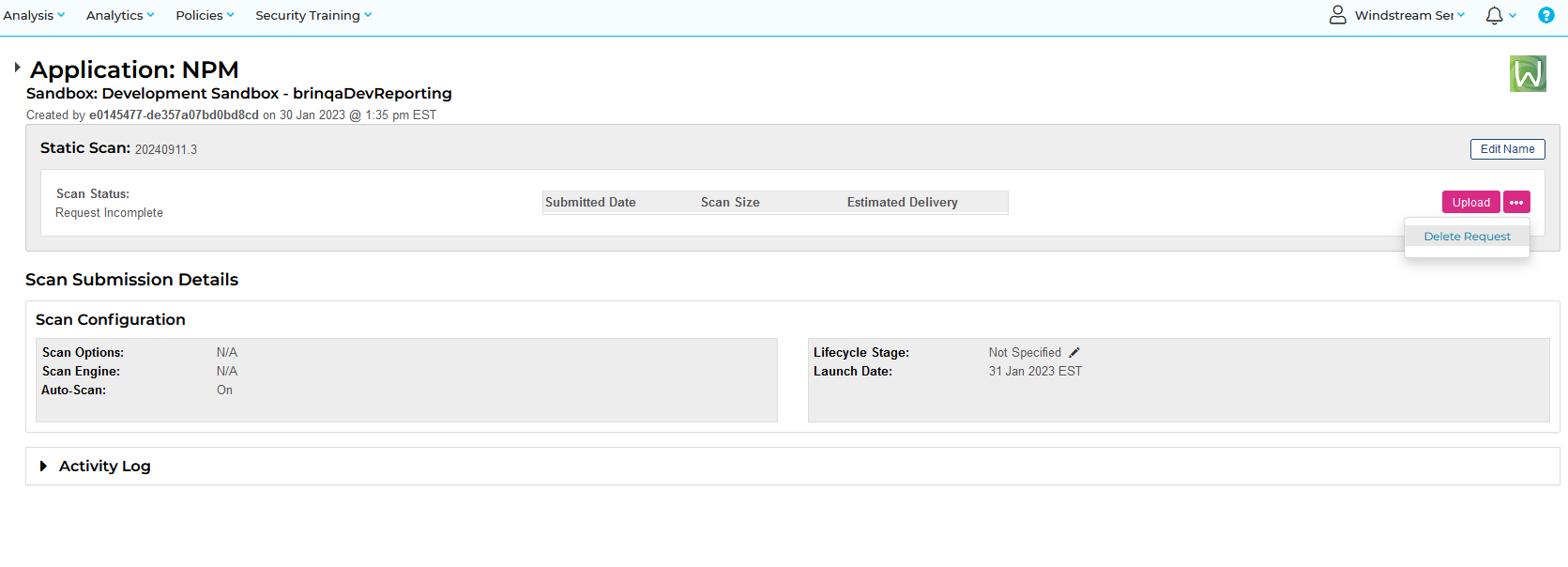
This is another case of simplifying a complex situation to make someone look bad: Cali lets you walk right out if you are stealing $950 or less. And ignoring the real problem (if you want to have all of these crimes investigated and prosecuted, your local/state taxes need to go up so departments can staff accordingly and enough jails can be built to house all of these criminals).
Every state has a law that differentiates between misdemeanor theft and felony theft. e.g. https://law.justia.com/codes/arkansas/title-5/subtitle-4/chapter-36/subchapter-1/section-5-36-103/ for Arkansas at $1000. I think most people would agree that someone who steals ten dollars worth of merchandise and someone who steals three grand worth of merchandise should get different punishments. Punishments are generally defined along with the classification of the crime. And each state’s law reflects this. Different states have different dollar amounts — and $950 sounds like a lot of money. But compared to the other states? California’s demarcation is pretty middle of the pack.
Unfortunately the entire criminal justice system is overloaded. Police may be too busy to deal with your theft complaint. The prosecutor may not get around to filing charges. And what happens if they do get a conviction? Now we need to find somewhere to detain the thief. And, again, if there’s a person stealing cars, a person kidnapping minors, and a person stealing the latest video game … ideally, we’d have resources to punish all of them. But we don’t. And I’d be way more upset if the kidnapper skated because they had a task force down at the GameStop gathering video from all the surrounding stores to track down this thief.
Prop 47 absolutely has some flaws. There’s a Prop 36 this year that seems like an attempt to fix some of the unintended consequences — two or more theft charges under $950 would be a felony. Stealing from multiple places that add up to over $950 would be a felony. Won’t know if that passes until November, but it’s not like all the liberals are dancing around saying this was 100% perfect and everyone else should do it too.
Alabama: $500
Alaska: $750
Arizona: $1,000
Arkansas: $1,000
California: $950
Colorado: $2,000
Connecticut: $2,000
Delaware: $1,500
Florida: $750
Georgia: $1,500
Hawaii: $750
Idaho: $1,000
Illinois: $500
Indiana: $750
Iowa: $300
Kansas: $1,500
Kentucky: $1,000
Louisiana: $1,000
Maine: $1,000
Maryland: $1,500
Massachusetts: $1,200
Michigan: $1,000
Minnesota: $1,000
Mississippi: $1,000
Missouri: $750
Montana: $1,500
Nebraska: $1,500
Nevada: $1,200
New Hampshire: $1,000
New Jersey: $200
New Mexico: $500
New York: $1,000
North Carolina: $1,000
North Dakota: $1,000
Ohio: $1,000
Oklahoma: $1,000
Oregon: $1,000
Pennsylvania: $2,000
Rhode Island: $1,500
South Carolina: $2,000
South Dakota: $1,000
Tennessee: $1,000
Texas: $2,500
Utah: $1,500
Vermont: $900
Virginia: $1,000
Washington: $750
West Virginia: $1,000
Wisconsin: $2,500
Wyoming: $1,000