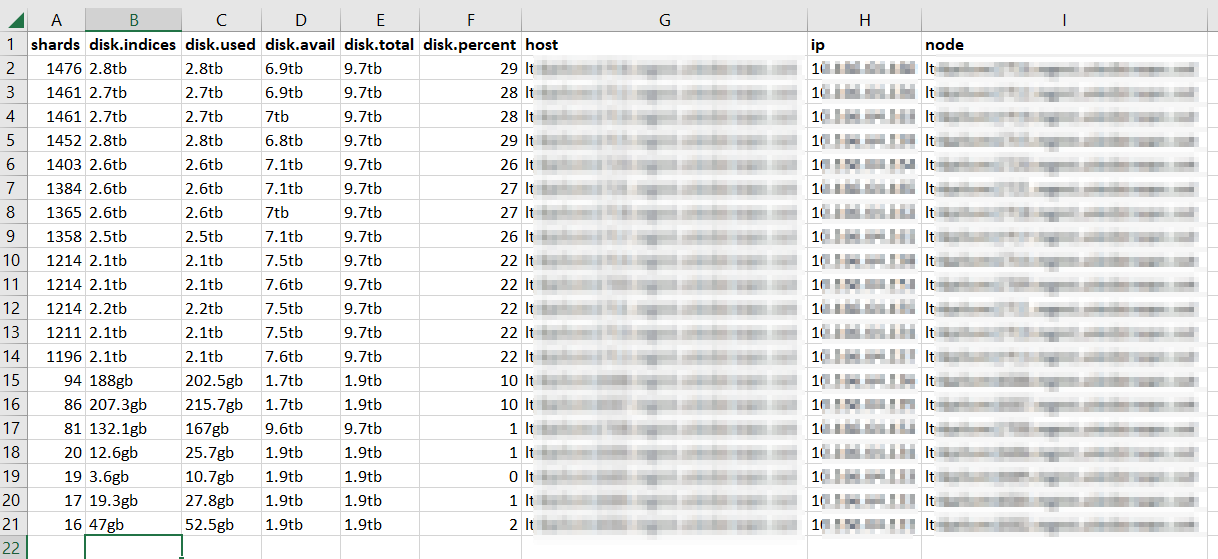
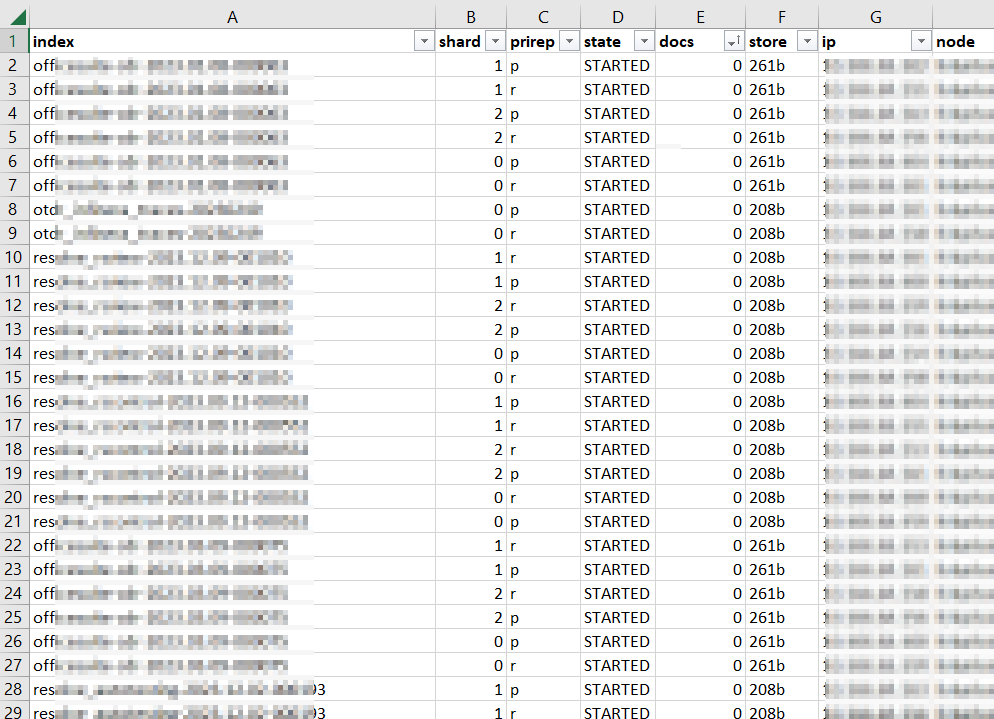
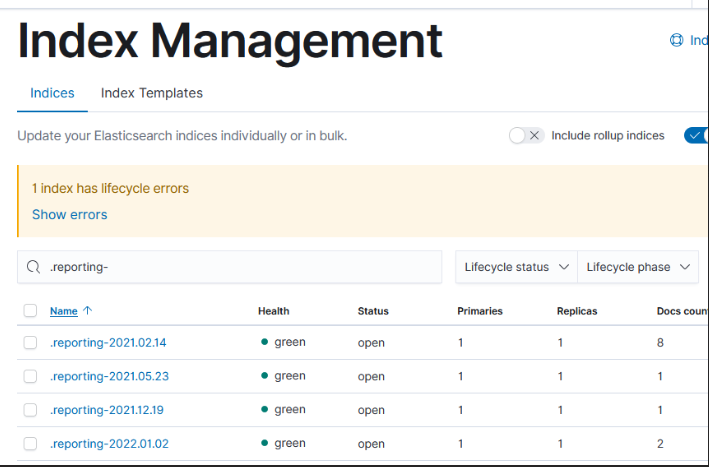
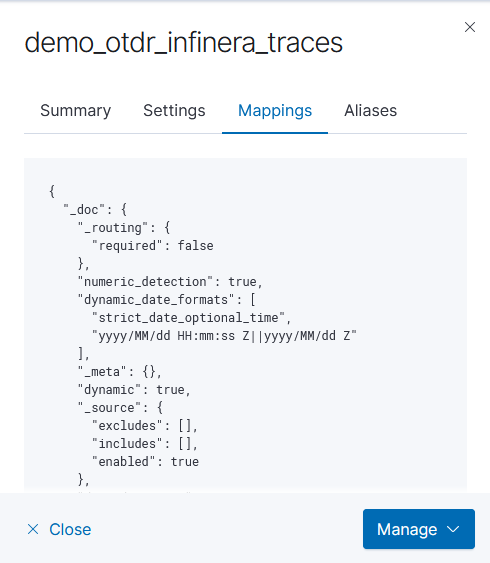
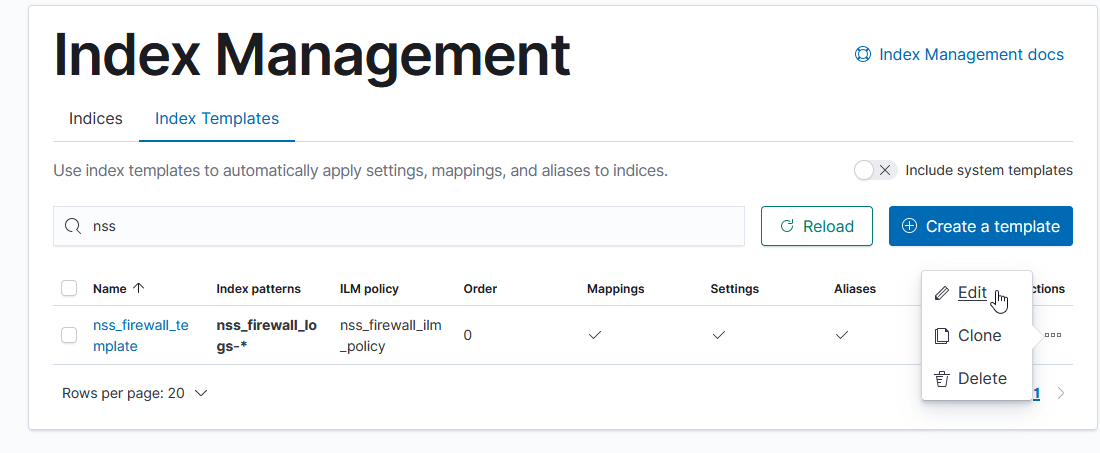
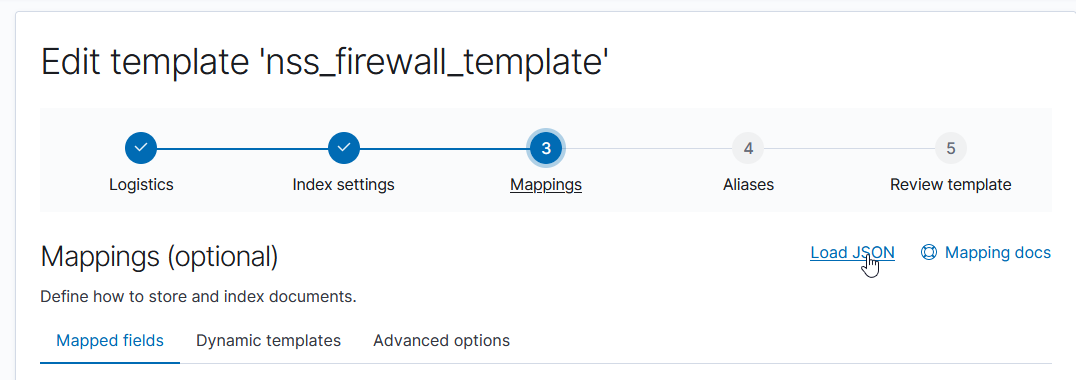
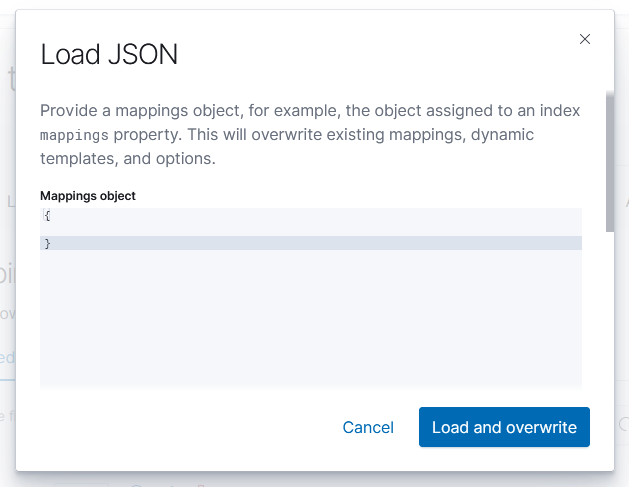
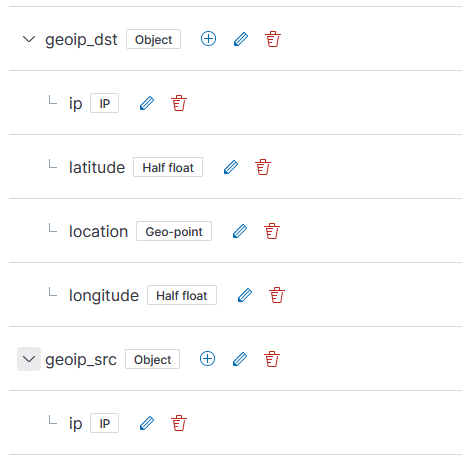
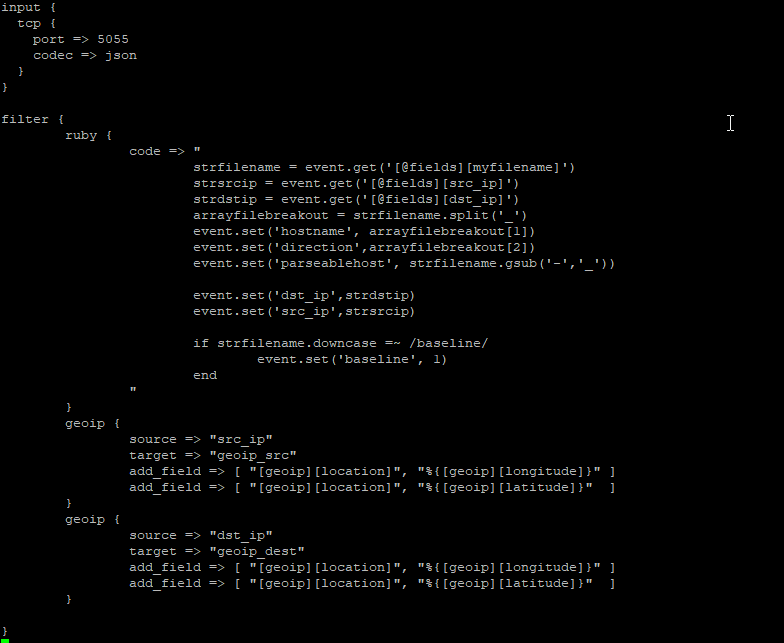
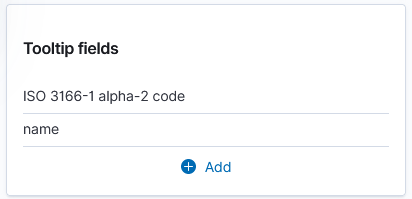
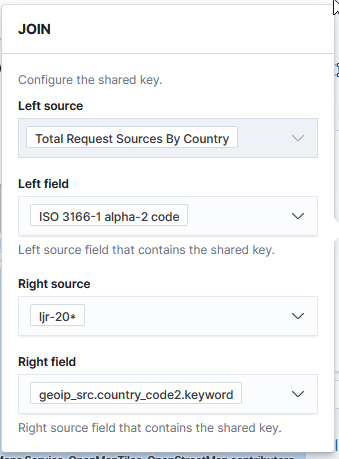
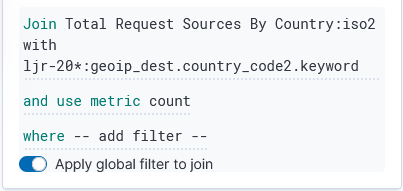
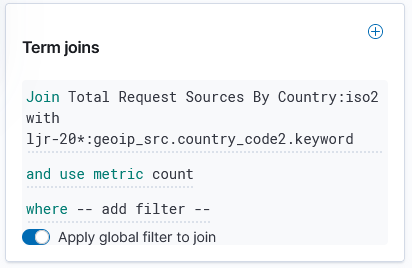
Which still produces a lot of output, but it’s all relevant to the pipeline that is experiencing a problem:
Using bundled JDK: /opt/elk/logstash/jdk
/opt/elk/logstash-8.13.1/vendor/bundle/jruby/3.1.0/gems/concurrent-ruby-1.1.9/lib/concurrent-ruby/concurrent/executor/java_thread_pool_executor.rb:13: warning: method redefined; discarding old to_int
/opt/elk/logstash-8.13.1/vendor/bundle/jruby/3.1.0/gems/concurrent-ruby-1.1.9/lib/concurrent-ruby/concurrent/executor/java_thread_pool_executor.rb:13: warning: method redefined; discarding old to_f
Sending Logstash logs to /opt/elk/logstash/logs which is now configured via log4j2.properties
[2024-10-23T10:47:36,364][INFO ][logstash.runner ] Log4j configuration path used is: /opt/elk/logstash/config/log4j2.properties
[2024-10-23T10:47:36,369][INFO ][logstash.runner ] Starting Logstash {"logstash.version"=>"8.13.1", "jruby.version"=>"jruby 9.4.5.0 (3.1.4) 2023-11-02 1abae2700f OpenJDK 64-Bit Server VM 17.0.10+7 on 17.0.10+7 +indy +jit [x86_64-linux]"}
[2024-10-23T10:47:36,371][INFO ][logstash.runner ] JVM bootstrap flags: [-Xms1g, -Xmx1g, -Djava.awt.headless=true, -Dfile.encoding=UTF-8, -Djdk.io.File.enableADS=true, -Djruby.compile.invokedynamic=true, -Djruby.jit.threshold=0, -Djruby.regexp.interruptible=true, -XX:+HeapDumpOnOutOfMemoryError, -Djava.security.egd=file:/dev/urandom, -Dlog4j2.isThreadContextMapInheritable=true, --add-opens=java.base/sun.nio.ch=ALL-UNNAMED, --add-opens=java.base/java.io=ALL-UNNAMED, --add-exports=jdk.compiler/com.sun.tools.javac.api=ALL-UNNAMED, --add-exports=jdk.compiler/com.sun.tools.javac.file=ALL-UNNAMED, --add-exports=jdk.compiler/com.sun.tools.javac.parser=ALL-UNNAMED, --add-exports=jdk.compiler/com.sun.tools.javac.tree=ALL-UNNAMED, --add-exports=jdk.compiler/com.sun.tools.javac.util=ALL-UNNAMED, --add-opens=java.base/java.security=ALL-UNNAMED, --add-opens=java.base/java.io=ALL-UNNAMED, --add-opens=java.base/java.nio.channels=ALL-UNNAMED, --add-opens=java.base/sun.nio.ch=ALL-UNNAMED, --add-opens=java.management/sun.management=ALL-UNNAMED, -Dio.netty.allocator.maxOrder=11]
[2024-10-23T10:47:36,376][DEBUG][logstash.modules.scaffold] Found module {:module_name=>"fb_apache", :directory=>"/opt/elk/logstash/modules/fb_apache/configuration"}
[2024-10-23T10:47:36,376][DEBUG][logstash.plugins.registry] Adding plugin to the registry {:name=>"fb_apache", :type=>:modules, :class=>#<LogStash::Modules::Scaffold:0x14917e38 @directory="/opt/elk/logstash/modules/fb_apache/configuration", @module_name="fb_apache", @kibana_version_parts=["6", "0", "0"]>}
[2024-10-23T10:47:36,379][DEBUG][logstash.modules.scaffold] Found module {:module_name=>"netflow", :directory=>"/opt/elk/logstash/modules/netflow/configuration"}
[2024-10-23T10:47:36,379][DEBUG][logstash.plugins.registry] Adding plugin to the registry {:name=>"netflow", :type=>:modules, :class=>#<LogStash::Modules::Scaffold:0x5909021c @directory="/opt/elk/logstash/modules/netflow/configuration", @module_name="netflow", @kibana_version_parts=["6", "0", "0"]>}
[2024-10-23T10:47:36,408][DEBUG][logstash.runner ] Setting global FieldReference escape style: none
[2024-10-23T10:47:36,606][DEBUG][logstash.runner ] -------- Logstash Settings (* means modified) ---------
[2024-10-23T10:47:36,606][DEBUG][logstash.runner ] allow_superuser: true
[2024-10-23T10:47:36,606][DEBUG][logstash.runner ] node.name: "logstashhost.example.net"
[2024-10-23T10:47:36,606][DEBUG][logstash.runner ] *path.config: "/opt/elk/logstash/config/ljr_testing.conf"
[2024-10-23T10:47:36,607][DEBUG][logstash.runner ] path.data: "/opt/elk/logstash/data"
[2024-10-23T10:47:36,607][DEBUG][logstash.runner ] modules.cli: #<Java::OrgLogstashUtil::ModulesSettingArray: []>
[2024-10-23T10:47:36,607][DEBUG][logstash.runner ] modules: []
[2024-10-23T10:47:36,607][DEBUG][logstash.runner ] modules_list: []
[2024-10-23T10:47:36,607][DEBUG][logstash.runner ] modules_variable_list: []
[2024-10-23T10:47:36,607][DEBUG][logstash.runner ] modules_setup: false
[2024-10-23T10:47:36,607][DEBUG][logstash.runner ] config.test_and_exit: false
[2024-10-23T10:47:36,607][DEBUG][logstash.runner ] config.reload.automatic: false
[2024-10-23T10:47:36,607][DEBUG][logstash.runner ] config.reload.interval: #<Java::OrgLogstashUtil::TimeValue:0x4e8224cf>
[2024-10-23T10:47:36,607][DEBUG][logstash.runner ] config.support_escapes: false
[2024-10-23T10:47:36,607][DEBUG][logstash.runner ] config.field_reference.escape_style: "none"
[2024-10-23T10:47:36,607][DEBUG][logstash.runner ] event_api.tags.illegal: "rename"
[2024-10-23T10:47:36,607][DEBUG][logstash.runner ] metric.collect: true
[2024-10-23T10:47:36,607][DEBUG][logstash.runner ] pipeline.id: "main"
[2024-10-23T10:47:36,608][DEBUG][logstash.runner ] pipeline.system: false
[2024-10-23T10:47:36,608][DEBUG][logstash.runner ] pipeline.workers: 4
[2024-10-23T10:47:36,608][DEBUG][logstash.runner ] pipeline.batch.size: 125
[2024-10-23T10:47:36,608][DEBUG][logstash.runner ] pipeline.batch.delay: 50
[2024-10-23T10:47:36,608][DEBUG][logstash.runner ] pipeline.unsafe_shutdown: false
[2024-10-23T10:47:36,608][DEBUG][logstash.runner ] pipeline.reloadable: true
[2024-10-23T10:47:36,608][DEBUG][logstash.runner ] pipeline.plugin_classloaders: false
[2024-10-23T10:47:36,608][DEBUG][logstash.runner ] pipeline.separate_logs: false
[2024-10-23T10:47:36,608][DEBUG][logstash.runner ] pipeline.ordered: "auto"
[2024-10-23T10:47:36,608][DEBUG][logstash.runner ] pipeline.ecs_compatibility: "v8"
[2024-10-23T10:47:36,608][DEBUG][logstash.runner ] path.plugins: []
[2024-10-23T10:47:36,608][DEBUG][logstash.runner ] config.debug: false
[2024-10-23T10:47:36,608][DEBUG][logstash.runner ] *log.level: "debug" (default: "info")
[2024-10-23T10:47:36,609][DEBUG][logstash.runner ] version: false
[2024-10-23T10:47:36,609][DEBUG][logstash.runner ] help: false
[2024-10-23T10:47:36,609][DEBUG][logstash.runner ] enable-local-plugin-development: false
[2024-10-23T10:47:36,609][DEBUG][logstash.runner ] log.format: "plain"
[2024-10-23T10:47:36,609][DEBUG][logstash.runner ] api.enabled: true
[2024-10-23T10:47:36,609][DEBUG][logstash.runner ] *api.http.host: "10.166.25.148" (via deprecated `http.host`; default: "127.0.0.1")
[2024-10-23T10:47:36,609][DEBUG][logstash.runner ] *http.host: "10.166.25.148"
[2024-10-23T10:47:36,609][DEBUG][logstash.runner ] *api.http.port: 9600..9600 (via deprecated `http.port`; default: 9600..9700)
[2024-10-23T10:47:36,609][DEBUG][logstash.runner ] *http.port: 9600..9600
[2024-10-23T10:47:36,609][DEBUG][logstash.runner ] api.environment: "production"
[2024-10-23T10:47:36,609][DEBUG][logstash.runner ] api.auth.type: "none"
[2024-10-23T10:47:36,609][DEBUG][logstash.runner ] api.auth.basic.password_policy.mode: "WARN"
[2024-10-23T10:47:36,610][DEBUG][logstash.runner ] api.auth.basic.password_policy.length.minimum: 8
[2024-10-23T10:47:36,610][DEBUG][logstash.runner ] api.auth.basic.password_policy.include.upper: "REQUIRED"
[2024-10-23T10:47:36,610][DEBUG][logstash.runner ] api.auth.basic.password_policy.include.lower: "REQUIRED"
[2024-10-23T10:47:36,610][DEBUG][logstash.runner ] api.auth.basic.password_policy.include.digit: "REQUIRED"
[2024-10-23T10:47:36,610][DEBUG][logstash.runner ] api.auth.basic.password_policy.include.symbol: "OPTIONAL"
[2024-10-23T10:47:36,610][DEBUG][logstash.runner ] api.ssl.enabled: false
[2024-10-23T10:47:36,610][DEBUG][logstash.runner ] api.ssl.supported_protocols: []
[2024-10-23T10:47:36,610][DEBUG][logstash.runner ] queue.type: "memory"
[2024-10-23T10:47:36,610][DEBUG][logstash.runner ] queue.drain: false
[2024-10-23T10:47:36,610][DEBUG][logstash.runner ] queue.page_capacity: 67108864
[2024-10-23T10:47:36,610][DEBUG][logstash.runner ] queue.max_bytes: 1073741824
[2024-10-23T10:47:36,610][DEBUG][logstash.runner ] queue.max_events: 0
[2024-10-23T10:47:36,610][DEBUG][logstash.runner ] queue.checkpoint.acks: 1024
[2024-10-23T10:47:36,611][DEBUG][logstash.runner ] queue.checkpoint.writes: 1024
[2024-10-23T10:47:36,611][DEBUG][logstash.runner ] queue.checkpoint.interval: 1000
[2024-10-23T10:47:36,611][DEBUG][logstash.runner ] queue.checkpoint.retry: true
[2024-10-23T10:47:36,611][DEBUG][logstash.runner ] dead_letter_queue.enable: false
[2024-10-23T10:47:36,611][DEBUG][logstash.runner ] dead_letter_queue.max_bytes: 1073741824
[2024-10-23T10:47:36,611][DEBUG][logstash.runner ] dead_letter_queue.flush_interval: 5000
[2024-10-23T10:47:36,611][DEBUG][logstash.runner ] dead_letter_queue.storage_policy: "drop_newer"
[2024-10-23T10:47:36,611][DEBUG][logstash.runner ] slowlog.threshold.warn: #<Java::OrgLogstashUtil::TimeValue:0x3436da82>
[2024-10-23T10:47:36,611][DEBUG][logstash.runner ] slowlog.threshold.info: #<Java::OrgLogstashUtil::TimeValue:0x1001ede3>
[2024-10-23T10:47:36,611][DEBUG][logstash.runner ] slowlog.threshold.debug: #<Java::OrgLogstashUtil::TimeValue:0x41820105>
[2024-10-23T10:47:36,611][DEBUG][logstash.runner ] slowlog.threshold.trace: #<Java::OrgLogstashUtil::TimeValue:0x2bb4b203>
[2024-10-23T10:47:36,611][DEBUG][logstash.runner ] keystore.classname: "org.logstash.secret.store.backend.JavaKeyStore"
[2024-10-23T10:47:36,612][DEBUG][logstash.runner ] keystore.file: "/opt/elk/logstash/config/logstash.keystore"
[2024-10-23T10:47:36,612][DEBUG][logstash.runner ] *monitoring.cluster_uuid: "hosq-h4ESECe63l2DvgymA"
[2024-10-23T10:47:36,612][DEBUG][logstash.runner ] path.queue: "/opt/elk/logstash/data/queue"
[2024-10-23T10:47:36,612][DEBUG][logstash.runner ] path.dead_letter_queue: "/opt/elk/logstash/data/dead_letter_queue"
[2024-10-23T10:47:36,612][DEBUG][logstash.runner ] path.settings: "/opt/elk/logstash/config"
[2024-10-23T10:47:36,612][DEBUG][logstash.runner ] path.logs: "/opt/elk/logstash/logs"
[2024-10-23T10:47:36,612][DEBUG][logstash.runner ] xpack.monitoring.enabled: false
[2024-10-23T10:47:36,612][DEBUG][logstash.runner ] xpack.monitoring.elasticsearch.hosts: ["http://localhost:9200"]
[2024-10-23T10:47:36,612][DEBUG][logstash.runner ] xpack.monitoring.collection.interval: #<Java::OrgLogstashUtil::TimeValue:0x35f2b220>
[2024-10-23T10:47:36,612][DEBUG][logstash.runner ] xpack.monitoring.collection.timeout_interval: #<Java::OrgLogstashUtil::TimeValue:0x296c863c>
[2024-10-23T10:47:36,612][DEBUG][logstash.runner ] xpack.monitoring.elasticsearch.username: "logstash_system"
[2024-10-23T10:47:36,612][DEBUG][logstash.runner ] xpack.monitoring.elasticsearch.ssl.verification_mode: "full"
[2024-10-23T10:47:36,612][DEBUG][logstash.runner ] xpack.monitoring.elasticsearch.ssl.cipher_suites: []
[2024-10-23T10:47:36,613][DEBUG][logstash.runner ] xpack.monitoring.elasticsearch.sniffing: false
[2024-10-23T10:47:36,613][DEBUG][logstash.runner ] xpack.monitoring.collection.pipeline.details.enabled: true
[2024-10-23T10:47:36,613][DEBUG][logstash.runner ] xpack.monitoring.collection.config.enabled: true
[2024-10-23T10:47:36,613][DEBUG][logstash.runner ] monitoring.enabled: false
[2024-10-23T10:47:36,613][DEBUG][logstash.runner ] monitoring.elasticsearch.hosts: ["http://localhost:9200"]
[2024-10-23T10:47:36,613][DEBUG][logstash.runner ] monitoring.collection.interval: #<Java::OrgLogstashUtil::TimeValue:0x6d5f9907>
[2024-10-23T10:47:36,613][DEBUG][logstash.runner ] monitoring.collection.timeout_interval: #<Java::OrgLogstashUtil::TimeValue:0x69d0fac0>
[2024-10-23T10:47:36,613][DEBUG][logstash.runner ] monitoring.elasticsearch.username: "logstash_system"
[2024-10-23T10:47:36,613][DEBUG][logstash.runner ] monitoring.elasticsearch.ssl.verification_mode: "full"
[2024-10-23T10:47:36,613][DEBUG][logstash.runner ] monitoring.elasticsearch.ssl.cipher_suites: []
[2024-10-23T10:47:36,613][DEBUG][logstash.runner ] monitoring.elasticsearch.sniffing: false
[2024-10-23T10:47:36,613][DEBUG][logstash.runner ] monitoring.collection.pipeline.details.enabled: true
[2024-10-23T10:47:36,613][DEBUG][logstash.runner ] monitoring.collection.config.enabled: true
[2024-10-23T10:47:36,613][DEBUG][logstash.runner ] node.uuid: ""
[2024-10-23T10:47:36,613][DEBUG][logstash.runner ] xpack.geoip.downloader.endpoint: "https://geoip.elastic.co/v1/database"
[2024-10-23T10:47:36,614][DEBUG][logstash.runner ] xpack.geoip.downloader.poll.interval: #<Java::OrgLogstashUtil::TimeValue:0x52e2ea7a>
[2024-10-23T10:47:36,614][DEBUG][logstash.runner ] xpack.geoip.downloader.enabled: true
[2024-10-23T10:47:36,614][DEBUG][logstash.runner ] xpack.management.enabled: false
[2024-10-23T10:47:36,614][DEBUG][logstash.runner ] xpack.management.logstash.poll_interval: #<Java::OrgLogstashUtil::TimeValue:0x6d5a43c1>
[2024-10-23T10:47:36,614][DEBUG][logstash.runner ] xpack.management.pipeline.id: ["main"]
[2024-10-23T10:47:36,614][DEBUG][logstash.runner ] xpack.management.elasticsearch.username: "logstash_system"
[2024-10-23T10:47:36,614][DEBUG][logstash.runner ] xpack.management.elasticsearch.hosts: ["https://localhost:9200"]
[2024-10-23T10:47:36,614][DEBUG][logstash.runner ] xpack.management.elasticsearch.ssl.cipher_suites: []
[2024-10-23T10:47:36,614][DEBUG][logstash.runner ] xpack.management.elasticsearch.ssl.verification_mode: "full"
[2024-10-23T10:47:36,614][DEBUG][logstash.runner ] xpack.management.elasticsearch.sniffing: false
[2024-10-23T10:47:36,614][DEBUG][logstash.runner ] --------------- Logstash Settings -------------------
[2024-10-23T10:47:36,640][WARN ][logstash.config.source.multilocal] Ignoring the 'pipelines.yml' file because modules or command line options are specified
[2024-10-23T10:47:36,682][DEBUG][logstash.agent ] Initializing API WebServer {"api.http.host"=>"10.166.25.148", "api.http.port"=>9600..9600, "api.ssl.enabled"=>false, "api.auth.type"=>"none", "api.environment"=>"production"}
[2024-10-23T10:47:36,790][DEBUG][logstash.api.service ] [api-service] start
[2024-10-23T10:47:36,868][DEBUG][logstash.agent ] Setting up metric collection
[2024-10-23T10:47:36,912][DEBUG][logstash.instrument.periodicpoller.os] Starting {:polling_interval=>5, :polling_timeout=>120}
[2024-10-23T10:47:37,121][DEBUG][logstash.instrument.periodicpoller.jvm] Starting {:polling_interval=>5, :polling_timeout=>120}
[2024-10-23T10:47:37,178][DEBUG][logstash.instrument.periodicpoller.jvm] collector name {:name=>"G1 Young Generation"}
[2024-10-23T10:47:37,182][DEBUG][logstash.instrument.periodicpoller.jvm] collector name {:name=>"G1 Old Generation"}
[2024-10-23T10:47:37,196][DEBUG][logstash.instrument.periodicpoller.persistentqueue] Starting {:polling_interval=>5, :polling_timeout=>120}
[2024-10-23T10:47:37,205][DEBUG][logstash.instrument.periodicpoller.deadletterqueue] Starting {:polling_interval=>5, :polling_timeout=>120}
[2024-10-23T10:47:37,208][DEBUG][logstash.instrument.periodicpoller.flowrate] Starting {:polling_interval=>5, :polling_timeout=>120}
[2024-10-23T10:47:37,519][DEBUG][logstash.agent ] Starting agent
[2024-10-23T10:47:37,530][DEBUG][logstash.agent ] Starting API WebServer (puma)
[2024-10-23T10:47:37,586][DEBUG][logstash.config.source.local.configpathloader] Reading config file {:config_file=>"/opt/elk/logstash/config/ljr_testing.conf"}
[2024-10-23T10:47:37,596][DEBUG][logstash.agent ] Trying to start API WebServer {:port=>9600, :ssl_enabled=>false}
[2024-10-23T10:47:37,657][DEBUG][logstash.agent ] Converging pipelines state {:actions_count=>1}
[2024-10-23T10:47:37,669][DEBUG][logstash.agent ] Executing action {:action=>LogStash::PipelineAction::Create/pipeline_id:main}
[2024-10-23T10:47:37,683][DEBUG][org.logstash.secret.store.SecretStoreFactory] Attempting to exists or secret store with implementation: org.logstash.secret.store.backend.JavaKeyStore
[2024-10-23T10:47:37,758][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600, :ssl_enabled=>false}
[2024-10-23T10:47:38,172][INFO ][org.reflections.Reflections] Reflections took 86 ms to scan 1 urls, producing 132 keys and 468 values
[2024-10-23T10:47:38,191][DEBUG][org.logstash.secret.store.SecretStoreFactory] Attempting to exists or secret store with implementation: org.logstash.secret.store.backend.JavaKeyStore
[2024-10-23T10:47:38,219][DEBUG][logstash.plugins.registry] On demand adding plugin to the registry {:name=>"generator", :type=>"input", :class=>LogStash::Inputs::Generator}
[2024-10-23T10:47:38,289][DEBUG][logstash.plugins.registry] On demand adding plugin to the registry {:name=>"json", :type=>"codec", :class=>LogStash::Codecs::JSON}
[2024-10-23T10:47:38,318][DEBUG][logstash.codecs.json ] config LogStash::Codecs::JSON/@id = "json_3f7d0e36-fb51-4b2a-993f-4287698b2b63"
[2024-10-23T10:47:38,319][DEBUG][logstash.codecs.json ] config LogStash::Codecs::JSON/@enable_metric = true
[2024-10-23T10:47:38,319][DEBUG][logstash.codecs.json ] config LogStash::Codecs::JSON/@charset = "UTF-8"
[2024-10-23T10:47:38,346][DEBUG][logstash.inputs.generator] config LogStash::Inputs::Generator/@count = 1
[2024-10-23T10:47:38,350][DEBUG][logstash.inputs.generator] config LogStash::Inputs::Generator/@codec = <LogStash::Codecs::JSON id=>"json_3f7d0e36-fb51-4b2a-993f-4287698b2b63", enable_metric=>true, charset=>"UTF-8">
[2024-10-23T10:47:38,351][DEBUG][logstash.inputs.generator] config LogStash::Inputs::Generator/@id = "ca89bb64fce3017f652b7d9e15198c67ecfbcea7435cac7e2316ed9f567a0820"
[2024-10-23T10:47:38,351][DEBUG][logstash.inputs.generator] config LogStash::Inputs::Generator/@message = "{\"test\": \"data\"}"
[2024-10-23T10:47:38,351][DEBUG][logstash.inputs.generator] config LogStash::Inputs::Generator/@enable_metric = true
[2024-10-23T10:47:38,351][DEBUG][logstash.inputs.generator] config LogStash::Inputs::Generator/@add_field = {}
[2024-10-23T10:47:38,351][DEBUG][logstash.inputs.generator] config LogStash::Inputs::Generator/@threads = 1
[2024-10-23T10:47:38,392][DEBUG][logstash.plugins.registry] On demand adding plugin to the registry {:name=>"http", :type=>"output", :class=>LogStash::Outputs::Http}
[2024-10-23T10:47:38,405][DEBUG][logstash.codecs.json ] config LogStash::Codecs::JSON/@id = "json_523f376a-5ed8-44dc-a17c-ff9f1daad51a"
[2024-10-23T10:47:38,406][DEBUG][logstash.codecs.json ] config LogStash::Codecs::JSON/@enable_metric = true
[2024-10-23T10:47:38,406][DEBUG][logstash.codecs.json ] config LogStash::Codecs::JSON/@charset = "UTF-8"
[2024-10-23T10:47:38,413][ERROR][logstash.outputs.http ] Unknown setting 'ssl_verification_mode' for http
[2024-10-23T10:47:38,420][ERROR][logstash.agent ] Failed to execute action {:action=>LogStash::PipelineAction::Create/pipeline_id:main, :exception=>"Java::JavaLang::IllegalStateException", :message=>"Unable to configure plugins: (ConfigurationError) Something is wrong with your configuration.", :backtrace=>["org.logstash.config.ir.CompiledPipeline.<init>(CompiledPipeline.java:120)", "org.logstash.execution.AbstractPipelineExt.initialize(AbstractPipelineExt.java:186)", "org.logstash.execution.AbstractPipelineExt$INVOKER$i$initialize.call(AbstractPipelineExt$INVOKER$i$initialize.gen)", "org.jruby.internal.runtime.methods.JavaMethod$JavaMethodN.call(JavaMethod.java:847)", "org.jruby.ir.runtime.IRRuntimeHelpers.instanceSuper(IRRuntimeHelpers.java:1319)", "org.jruby.ir.runtime.IRRuntimeHelpers.instanceSuperSplatArgs(IRRuntimeHelpers.java:1292)", "org.jruby.ir.targets.indy.InstanceSuperInvokeSite.invoke(InstanceSuperInvokeSite.java:30)", "opt.elk.logstash_minus_8_dot_13_dot_1.logstash_minus_core.lib.logstash.java_pipeline.RUBY$method$initialize$0(/opt/elk/logstash-8.13.1/logstash-core/lib/logstash/java_pipeline.rb:48)", "org.jruby.internal.runtime.methods.CompiledIRMethod.call(CompiledIRMethod.java:139)", "org.jruby.internal.runtime.methods.MixedModeIRMethod.call(MixedModeIRMethod.java:112)", "org.jruby.runtime.callsite.CachingCallSite.cacheAndCall(CachingCallSite.java:446)", "org.jruby.runtime.callsite.CachingCallSite.call(CachingCallSite.java:92)", "org.jruby.RubyClass.newInstance(RubyClass.java:931)", "org.jruby.RubyClass$INVOKER$i$newInstance.call(RubyClass$INVOKER$i$newInstance.gen)", "org.jruby.ir.targets.indy.InvokeSite.performIndirectCall(InvokeSite.java:735)", "org.jruby.ir.targets.indy.InvokeSite.invoke(InvokeSite.java:657)", "opt.elk.logstash_minus_8_dot_13_dot_1.logstash_minus_core.lib.logstash.pipeline_action.create.RUBY$method$execute$0(/opt/elk/logstash-8.13.1/logstash-core/lib/logstash/pipeline_action/create.rb:49)", "opt.elk.logstash_minus_8_dot_13_dot_1.logstash_minus_core.lib.logstash.pipeline_action.create.RUBY$method$execute$0$__VARARGS__(/opt/elk/logstash-8.13.1/logstash-core/lib/logstash/pipeline_action/create.rb:48)", "org.jruby.internal.runtime.methods.CompiledIRMethod.call(CompiledIRMethod.java:139)", "org.jruby.internal.runtime.methods.MixedModeIRMethod.call(MixedModeIRMethod.java:112)", "org.jruby.ir.targets.indy.InvokeSite.performIndirectCall(InvokeSite.java:735)", "org.jruby.ir.targets.indy.InvokeSite.invoke(InvokeSite.java:657)", "opt.elk.logstash_minus_8_dot_13_dot_1.logstash_minus_core.lib.logstash.agent.RUBY$block$converge_state$2(/opt/elk/logstash-8.13.1/logstash-core/lib/logstash/agent.rb:386)", "org.jruby.runtime.CompiledIRBlockBody.callDirect(CompiledIRBlockBody.java:141)", "org.jruby.runtime.IRBlockBody.call(IRBlockBody.java:64)", "org.jruby.runtime.IRBlockBody.call(IRBlockBody.java:58)", "org.jruby.runtime.Block.call(Block.java:144)", "org.jruby.RubyProc.call(RubyProc.java:352)", "org.jruby.internal.runtime.RubyRunnable.run(RubyRunnable.java:111)", "java.base/java.lang.Thread.run(Thread.java:840)"]}
[2024-10-23T10:47:38,448][DEBUG][logstash.agent ] Shutting down all pipelines {:pipelines_count=>0}
[2024-10-23T10:47:38,449][DEBUG][logstash.agent ] Converging pipelines state {:actions_count=>0}
[2024-10-23T10:47:38,452][DEBUG][logstash.instrument.periodicpoller.os] Stopping
[2024-10-23T10:47:38,457][DEBUG][logstash.instrument.periodicpoller.jvm] Stopping
[2024-10-23T10:47:38,458][DEBUG][logstash.instrument.periodicpoller.persistentqueue] Stopping
[2024-10-23T10:47:38,458][DEBUG][logstash.instrument.periodicpoller.deadletterqueue] Stopping
[2024-10-23T10:47:38,458][DEBUG][logstash.instrument.periodicpoller.flowrate] Stopping
[2024-10-23T10:47:38,483][DEBUG][logstash.agent ] API WebServer has stopped running
[2024-10-23T10:47:38,484][INFO ][logstash.runner ] Logstash shut down.
[2024-10-23T10:47:38,493][FATAL][org.logstash.Logstash ] Logstash stopped processing because of an error: (SystemExit) exit
org.jruby.exceptions.SystemExit: (SystemExit) exit
at org.jruby.RubyKernel.exit(org/jruby/RubyKernel.java:808) ~[jruby.jar:?]
at org.jruby.RubyKernel.exit(org/jruby/RubyKernel.java:767) ~[jruby.jar:?]
at opt.elk.logstash.lib.bootstrap.environment.<main>(/opt/elk/logstash/lib/bootstrap/environment.rb:90) ~[?:?]
logstashhost:config #