The first cut of code may contain … not best practice code. Sometimes this is just hard coding something you’ll want to compute / look up in the future. Hard coding user input isn’t a problem if my first cut is always searching for ABC123. Hard coding the system creds? Not good. You sort that before you actually deploy the code. But some old iteration of the file has MyP2s5w0rD sitting right there in plain text. That’s bad in a system that maintains file history! The quick/easy way to clean up passwords stashed within the history is to download the BFG JAR file.
For this test, I created a new repository in .\source then created three clones of the repo (.\clone1, .\clone2, and .\clone3). In each cloneX copy, I created a tX folder that has a file named ldapAuthTest.py — a file that contains a statically assigned password as
strSystemAccountPass = "MyP2s5w0rD"
The first thing I did was to redact the password in the files — this means anyone looking at HEAD won’t see the password. Source, clone1, and clone2 are all current. The clone3 copy has pulled all changes but has a local change committed but not merged.
To clean the password from the git history, first create a backup of your repo (just in case!). Then mirror the repo to work on it
mkdir mirror
cd mirror
git clone --mirror d:\git\testFilterBranch\source
Create file .\replacements.txt with the string to be redacted — in this case:
strSystemAccountPass = "MyP2s5w0rD"
Formatting notes for replacements.txt
MyP2s5w0rD # Replaces string with default ***REMOVED***
MyP2s4w0rD==>REDACTED # Replaces string using custom string REDACTED
MyP2s3w0rD==> # Replaces string with null -- i.e. removes the string
regex:strSystemAccountPass\s?=\s?"MyP2s2w0rD""==>REDACTED # Uses a regex match -- in this case we may or may not have a space around the equal sign
So, in my mirror folder, I have the replacement.txt file which defines which strings are replaced. I have a folder that contains the mirror of my repo.
lisa@FLEX3 /cygdrive/d/git/testFilterBranch/mirror
$ ls
replacements.txt source.git
To replace my “stuff”, run bfg using the –replace-text option. Because I only want to replace the text in files named ldapAuthTest.py, I also added the -fi option
java -jar ../bfg-1.14.0.jar --replace-text ..\replacements.txt -fi ldapAuthTest.py source.git
lisa@FLEX3 /cygdrive/d/git/testFilterBranch/mirror
$ java -jar ../bfg-1.14.0.jar --replace-text replacements.txt -fi ldapAuthTest.py source.git
Using repo : D:\git\testFilterBranch\mirror\source.git
Found 3 objects to protect
Found 2 commit-pointing refs : HEAD, refs/heads/master
Protected commits
-----------------
These are your protected commits, and so their contents will NOT be altered:
* commit 87f1b398 (protected by 'HEAD')
Cleaning
--------
Found 5 commits
Cleaning commits: 100% (5/5)
Cleaning commits completed in 613 ms.
Updating 1 Ref
--------------
Ref Before After
---------------------------------------
refs/heads/master | 87f1b398 | 919c8f0f
Updating references: 100% (1/1)
...Ref update completed in 151 ms.
Commit Tree-Dirt History
------------------------
Earliest Latest
| |
. D D D m
D = dirty commits (file tree fixed)
m = modified commits (commit message or parents changed)
. = clean commits (no changes to file tree)
Before After
-------------------------------------------
First modified commit | dc2cd935 | 8764f6f1
Last dirty commit | 9665c4e0 | ccdf0359
Changed files
-------------
Filename Before & After
-------------------------------------
ldapAuthTest.py | 25e79fa6 ? 4d12fdad
In total, 8 object ids were changed. Full details are logged here:
D:\git\testFilterBranch\mirror\source.git.bfg-report\2021-06-23\12-50-00
BFG run is complete! When ready, run: git reflog expire --expire=now --all && git gc --prune=now --aggressive
Check to make sure nothing looks abjectly wrong. Assuming the repo is sound, we’re ready to clean up and push these changes.
cd source.git
git reflog expire --expire=now --all && git gc --prune=now --aggressive
git push
Pulling the update from my source repo, I have merge conflicts
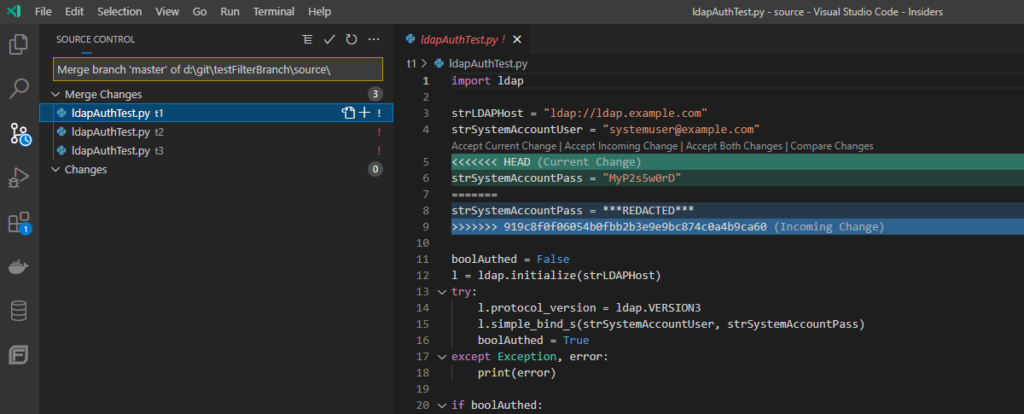
These are readily resolved and the source repo can be merged into my local copy.
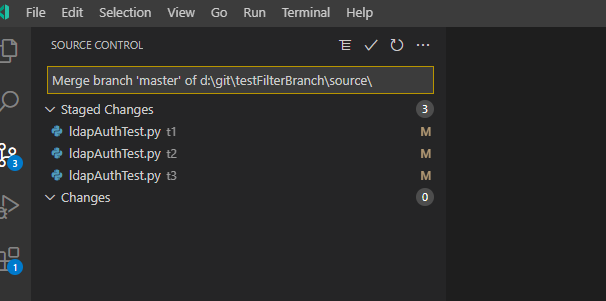
And the change I had committed but not pushed is still there.
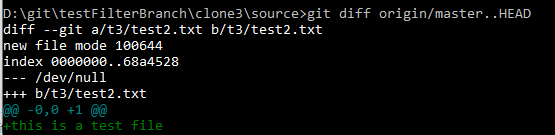
Pushing that change produces no errors
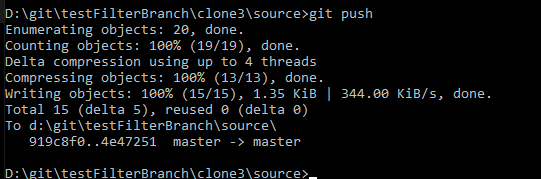
Now … pushing the bfg changes may not work. In my case, the real repo has a bunch of branchs and I am getting “non fast-forward merges”. To get the history changed, I need to do a force push. Not so good for the other developers! In that case, everyone should get their changes committed and pushed. The servers should be checked to ensure they are up to date. Then the force push can be done and everyone can pull the new “good” data (which, really, shouldn’t differ from the old data … it’s just the history that is being tweaked).