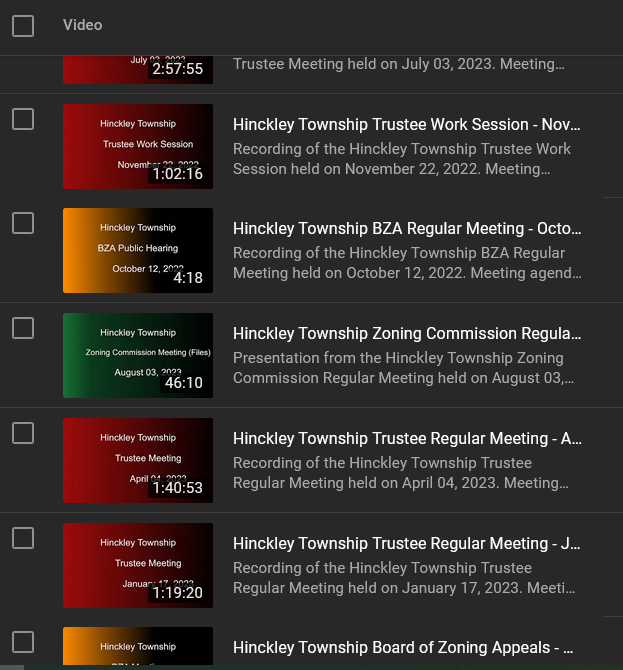
Instead of allowing YouTube to randomly pick a frame to use as the preview image, I have always made a title image for the Township meetings I post to YouTube. At first, this was a manual (and thus time consuming for a lot of videos). In the interim, I have created a script that generates the color gradient background and overlays text including the meeting type and date.
# Valid meeting types: "TrusteeRegular", "TrusteeSpecial", "TrusteeEmer", "TrusteeHearing", "BZAReg", "BZAHearing", "ZCReg", "ZCHearing"
strMeetingListSpreadsheet = 'MeetingList.xlsx'
from PIL import Image, ImageDraw, ImageFont
import pandas as pd
BLACK= (0,0,0)
WHITE = (255,255,255)
TRUSTEE_COLOR_PALETTE = [(156,12,12), (92,7,7), (0,0,0)]
BZA_COLOR_PALETTE = [(253,139,1), (91,51,0), (0,0,0)]
ZC_COLOR_PALETTE = [(24,113,56), (8,41,20), (0,0,0)]
MISC_COLOR_PALETTE = [(175,28,195), (55,9,61), (0,0,0)]
objFontMeetingTitle = ImageFont.truetype("/usr/share/fonts/liberation-sans/LiberationSans-Regular.ttf",115)
objFontMeetingTopic = ImageFont.truetype("/usr/share/fonts/liberation-sans/LiberationSans-Regular.ttf",115)
objFontMeetingDate = ImageFont.truetype("/usr/share/fonts/liberation-sans/LiberationSans-Italic.ttf",95)
class Point(object):
def __init__(self, x, y):
self.x, self.y = x, y
class Rect(object):
def __init__(self, x1, y1, x2, y2):
minx, maxx = (x1,x2) if x1 < x2 else (x2,x1)
miny, maxy = (y1,y2) if y1 < y2 else (y2,y1)
self.min = Point(minx, miny)
self.max = Point(maxx, maxy)
width = property(lambda self: self.max.x - self.min.x)
height = property(lambda self: self.max.y - self.min.y)
def gradient_color(minval, maxval, val, color_palette):
""" Computes intermediate RGB color of a value in the range of minval
to maxval (inclusive) based on a color_palette representing the range.
"""
max_index = len(color_palette)-1
delta = maxval - minval
if delta == 0:
delta = 1
v = float(val-minval) / delta * max_index
i1, i2 = int(v), min(int(v)+1, max_index)
(r1, g1, b1), (r2, g2, b2) = color_palette[i1], color_palette[i2]
f = v - i1
return int(r1 + f*(r2-r1)), int(g1 + f*(g2-g1)), int(b1 + f*(b2-b1))
def horz_gradient(draw, rect, color_func, color_palette):
minval, maxval = 1, len(color_palette)
delta = maxval - minval
width = float(rect.width) # Cache.
for x in range(rect.min.x, rect.max.x+1):
f = (x - rect.min.x) / width
val = minval + f * delta
color = color_func(minval, maxval, val, color_palette)
draw.line([(x, rect.min.y), (x, rect.max.y)], fill=color)
def vert_gradient(draw, rect, color_func, color_palette):
minval, maxval = 1, len(color_palette)
delta = maxval - minval
height = float(rect.height) # Cache.
for y in range(rect.min.y, rect.max.y+1):
f = (y - rect.min.y) / height
val = minval + f * delta
color = color_func(minval, maxval, val, color_palette)
draw.line([(rect.min.x, y), (rect.max.x, y)], fill=color)
if __name__ == '__main__':
df = pd.read_excel(strMeetingListSpreadsheet, sheet_name="Sheet1")
df = df.reset_index() # make sure indexes pair with number of rows
for index, row in df.iterrows():
strGraphicName = f"{row['Date'].strftime('%Y%d%m')}-{row['Type']}.png"
strMeetingType = row['Type']
# Draw a three color horizontal gradient.
region = Rect(0, 0, 1920, 1080)
width, height = region.max.x+1, region.max.y+1
image = Image.new("RGB", (width, height), BLACK)
draw = ImageDraw.Draw(image)
# Add meeting title
if strMeetingType == "TrusteeRegular":
horz_gradient(draw, region, gradient_color, TRUSTEE_COLOR_PALETTE)
draw.text((1670, 525),"Trustee Regular Meeting",WHITE,font=objFontMeetingTopic, anchor="rm")
elif strMeetingType == "TrusteeSpecial":
horz_gradient(draw, region, gradient_color, TRUSTEE_COLOR_PALETTE)
draw.text((1670, 525),"Trustee Special Meeting",WHITE,font=objFontMeetingTopic, anchor="rm")
elif strMeetingType == "TrusteeEmer":
horz_gradient(draw, region, gradient_color, TRUSTEE_COLOR_PALETTE)
draw.text((1670, 525),"Trustee Emergency Meeting",WHITE,font=objFontMeetingTopic, anchor="rm")
elif strMeetingType == "TrusteeHearing":
horz_gradient(draw, region, gradient_color, TRUSTEE_COLOR_PALETTE)
draw.text((1670, 525),"Trustee Public Hearing",WHITE,font=objFontMeetingTopic, anchor="rm")
elif strMeetingType == "BZAReg":
horz_gradient(draw, region, gradient_color, BZA_COLOR_PALETTE)
draw.text((1670, 525),"BZA Regular Meeting",WHITE,font=objFontMeetingTopic, anchor="rm")
elif strMeetingType == "BZAHearing":
horz_gradient(draw, region, gradient_color, BZA_COLOR_PALETTE)
draw.text((1670, 525),"BZA Public Hearing",WHITE,font=objFontMeetingTopic, anchor="rm")
elif strMeetingType == "ZCReg":
horz_gradient(draw, region, gradient_color, ZC_COLOR_PALETTE)
draw.text((1670, 525),"Zoning Commission Meeting",WHITE,font=objFontMeetingTopic, anchor="rm")
elif strMeetingType == "ZCHearing":
horz_gradient(draw, region, gradient_color, ZC_COLOR_PALETTE)
draw.text((1670, 525),"Zoning Commission Hearing",WHITE,font=objFontMeetingTopic, anchor="rm")
else:
horz_gradient(draw, region, gradient_color, MISC_COLOR_PALETTE)
draw.text((1670, 525),"Township Meeting",WHITE,font=objFontMeetingTopic, anchor="rm")
# Add township and date
draw.text((1070, 225),"Hinckley Township",WHITE,font=objFontMeetingTitle, anchor="rm")
draw.text((1770, 825),row['Date'].strftime('%B %d, %Y'),WHITE,font=objFontMeetingDate, anchor="rm")
image.save(strGraphicName, "PNG")
print(f"image saved as {strGraphicName}")
I have an Excel file which contains the meeting type code, a long meeting title that is used as the second line of the image, a date (and a MeetingDate that I use in my concat formulae that create the title and description for YouTube). To use an Excel date in concat, you need to use a TEXT formula with the text formatting string.
This allows me to have a consistent preview image for all of our postings without actually making dozens of files by hand.