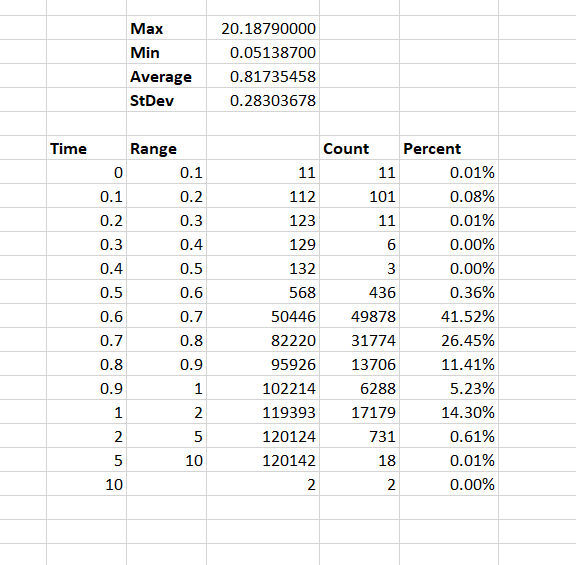
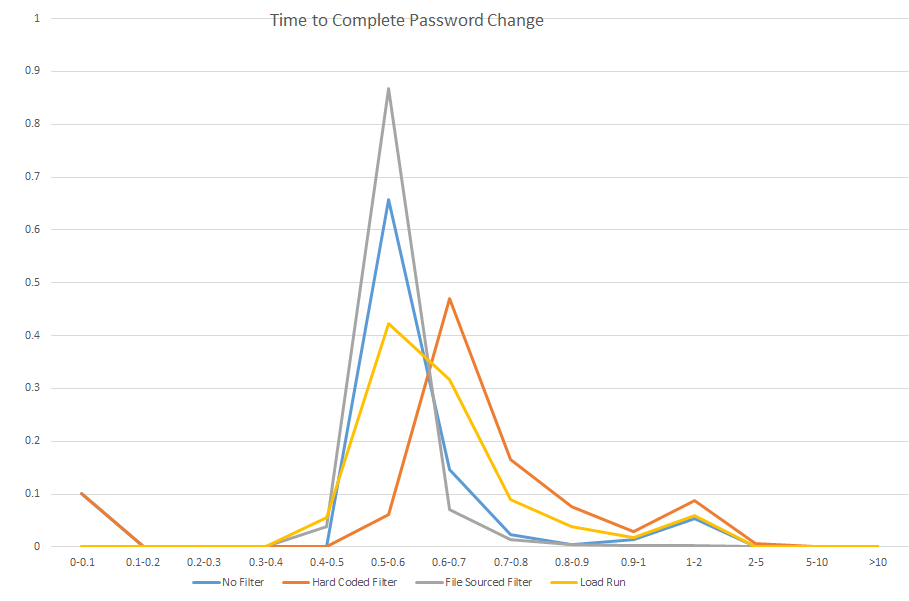
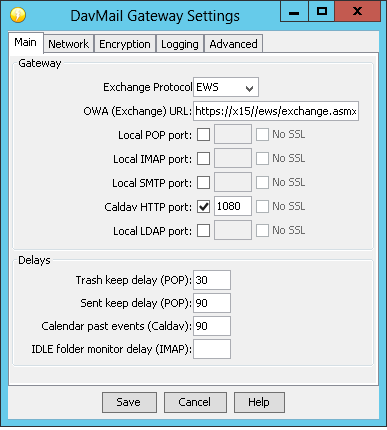
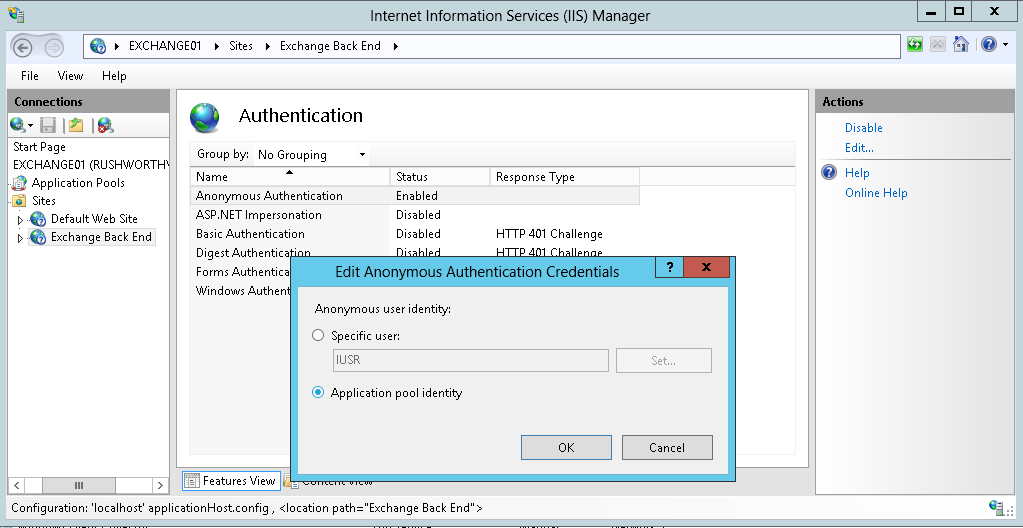
We started setting up the OpenHAB cloud server locally, and the instructions we had found omitted a few important steps. They say ‘install redis’ and ‘install mongodb’ without providing any sort of post-install configuration.
Redis
# This is optional – if you don’t set a password, you’ll just get a warning on launch that a password was supplied but none is required. While the service is, by default, bound to localhost … I still put a password on everything just to be safe
vi /etc/redis.conf # Your path may vary, this is Fedora. I've seen /etc/redis/redis.conf too
# Find the requirepass line and make one with your password
480 # requirepass foobared requirepass Y0|_|RP@s5w0rdG03s|-|3re
# Restart redis
service redis restart
Mongo:
# Install mongo (dnf install mongo mongo-server)
# start mongodb
service mongod start
# launch mongo client
mongo
# Create user in admin database
db.createUser({user: "yourDBUser", pwd: "yourDBUserPassword", roles: [{role: userAdminAnyDatabase", db: "admin"}]});
exit
# Modify mongodb server config to use security
vi /etc/mongod.conf
# remove remarkes before ‘security: ‘ and ‘authorization’ – set authorization to enabled:
99 # secutiry Options - Authorization and other security settings 100 security: 101 # Private key for cluster authentication 102 #keyFile: <string> 103 104 # Run with/without security (enabled|disabled, disabled by default) 105 authorization: enabled
# restart mongo
service mongod restart
#Launch mongo client supplying username and connecting to the admin database
mongo -uyourDBUser -p admin
# it will connect and prompt for password – you can use db.getUser to verify the account (but you just logged into it, so that’s a bit redundant)
MongoDB shell version: 3.2.12
Enter password:
connecting to: admin
> > db.getUser("yourDBUser");
{
"_id" : "admin.yourDBUser",
"user" : "yourDBUser",
"db" : "admin",
"roles" : [
{
"role" : "userAdminAnyDatabase",
"db" : "admin"
}
]
}
# Create the openhab database — mongo is a bit odd in that “use dbname” will switch context to that database if it exists *and* create the databse if it doesn’t exist. Bad for typo-prone types!
use yourDBName;
# Create the user in the openhab database
db.createUser({user: "yourDBUser", pwd: "yourDBUserPassword", roles: [{role: readWrite", db: "yourDBName"}]});
# You can use get user to verify it works
db.getUser("yourDBUser");
exit
# Now you can launch the mongo client connecting to the openhab database:
mongo -uyourDBUser -p yourDBName
# It will prompt for password and connect. At this point, you can use “node app.js” to launch the openhab cloud connector. Provided yourDBUser, yourDBUserPassword, and yourDBName match what you’ve used in the config file … it’ll connect and create a bunch of stuff