Someone deleted one of the packages from the Azure DevOps Maven feed … figured it would be easy enough to just re-publish the package. And they got an error:
409 Conflict – The version 1.2.3 of package.example.com has been deleted. It cannot be restored or pushed. (DevOps Activity ID: E7E4DEB1551D) -> [Help 1]
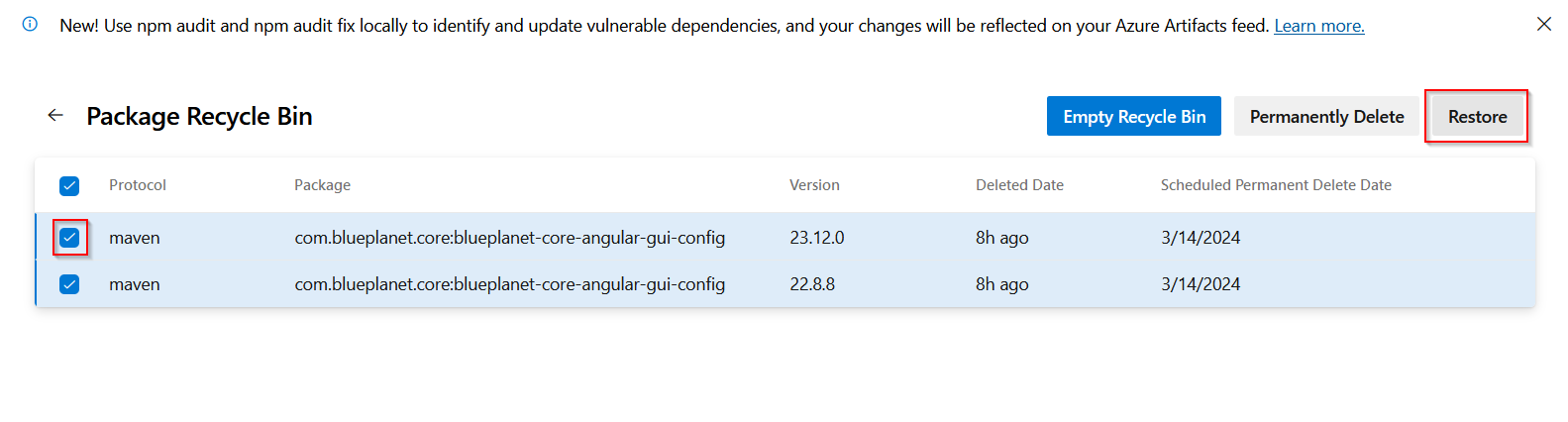
There’s some not-outlandish logic behind it because they don’t want half of the people to have this version 1.2.3 and the other half to get that version 1.2.3 … if it’s your code, just make it version 1.2.4. Unfortunately, this logic doesn’t hold up well when you’re publishing someone else’s package. Not like I can say “oops, we’ll use 23.13 now”. But you can restore deleted packages — from the feed, go into the recycle bin
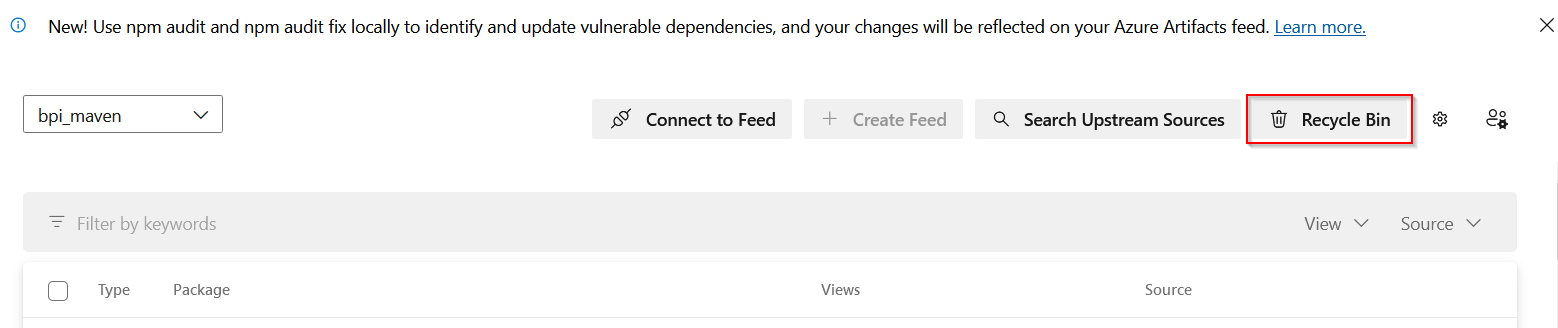
Check off the packages that were deleted in error & restore them