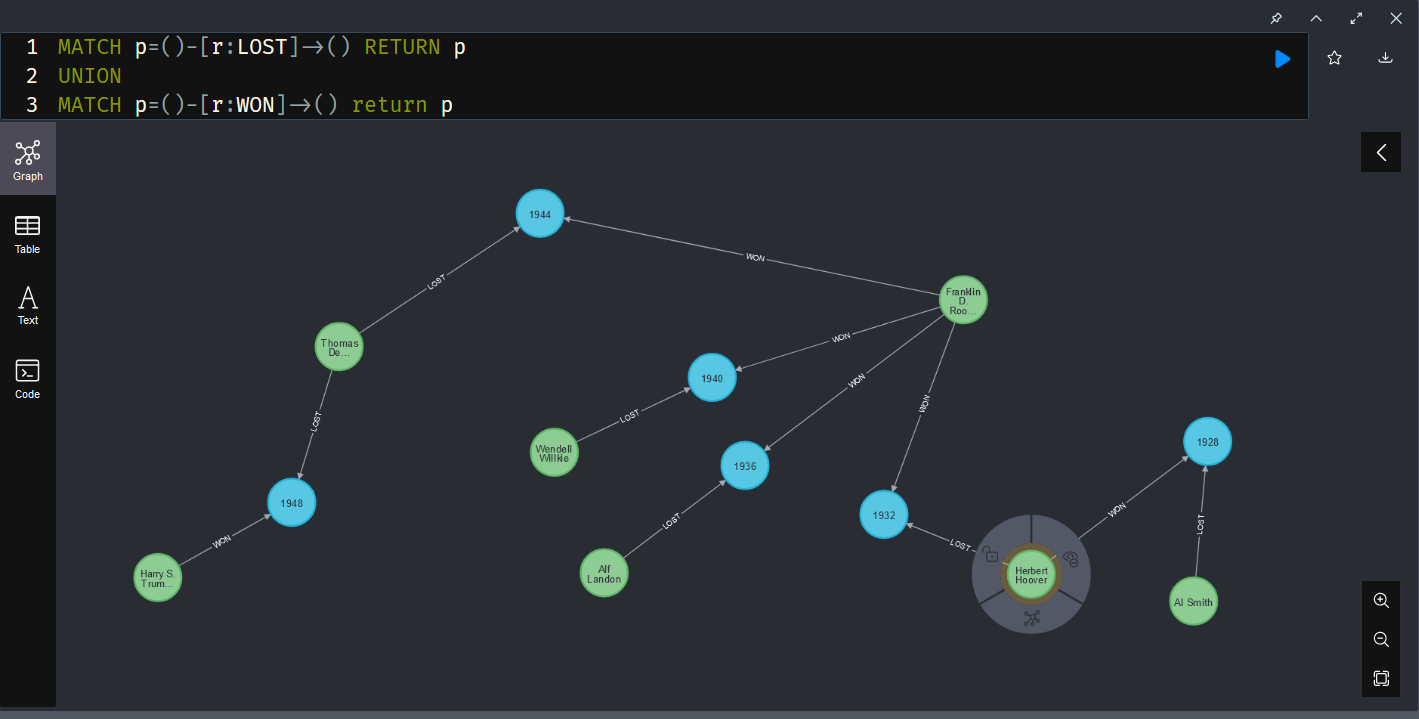
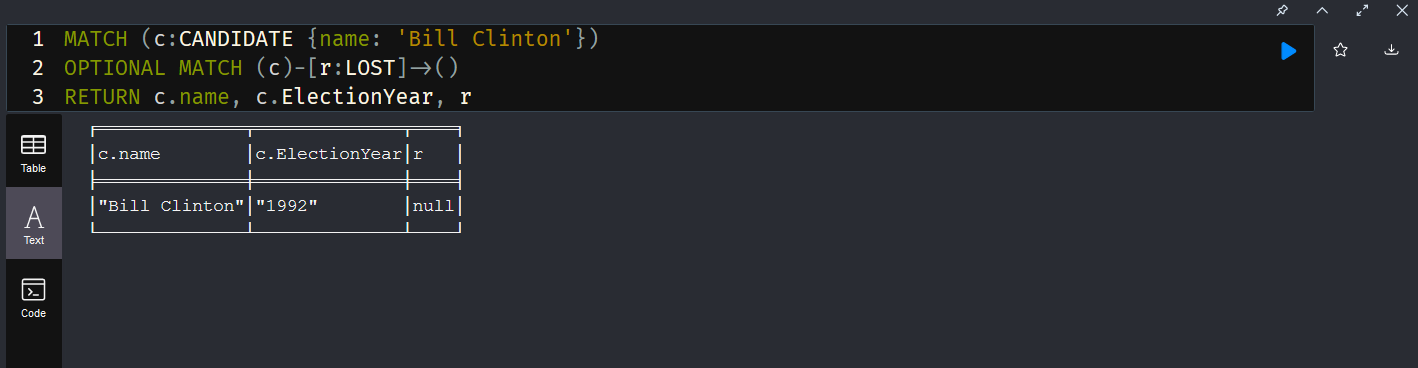
Since I seem to frequently acquire orphaned platforms with no documentation, I figure it would be good to figure out how to investigate an unknown NEO4J platform to see what it’s got. “SHOW” is very useful in these cases. The full list of SHOW commands is:
"ALIAS" "ALIASES" "ALL" "BTREE" "BUILT" "CONSTRAINT" "CONSTRAINTS" "CURRENT" "DATABASE" "DATABASES" "DEFAULT" "EXIST" "EXISTENCE" "EXISTS" "FULLTEXT" "FUNCTION" "FUNCTIONS" "HOME" "INDEX" "INDEXES" "KEY" "LOOKUP" "NODE" "POINT" "POPULATED" "PRIVILEGE" "PRIVILEGES" "PROCEDURE" "PROCEDURES" "PROPERTY" "RANGE" "REL" "RELATIONSHIP" "ROLE" "ROLES" "SERVER" "SERVERS" "SETTING" "SETTINGS" "SUPPORTED" "TEXT" "TRANSACTION" "TRANSACTIONS" "UNIQUE" "UNIQUENESS" "USER" "USERS"
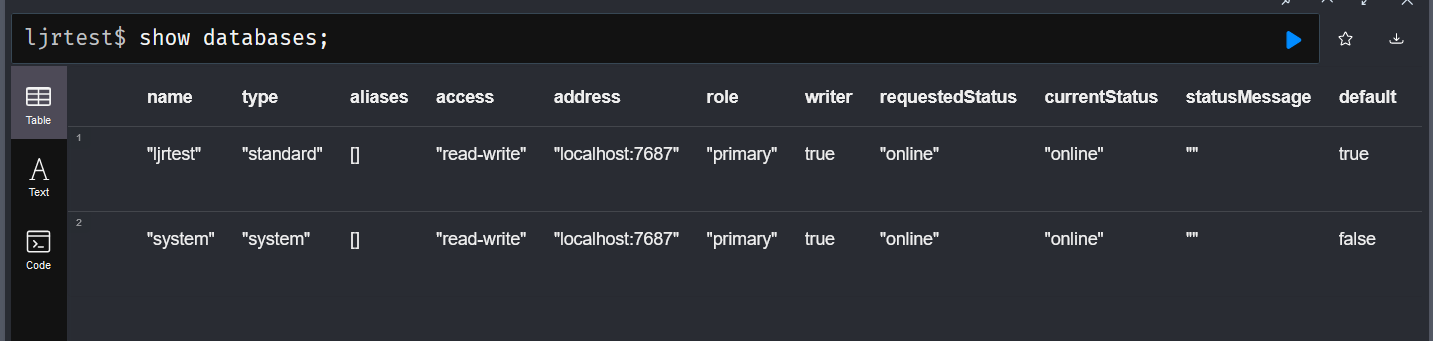
The most useful ones for figuring out what you’ve got … the “show databases” command I know from MySQL/MariaDB does what I expected – you can also include a specific database name, but “show database ljrtest” doesn’t appear to list any more information than the generic show databases command. .
There’s also a “show users” command that outputs the users in the database – although I’m using the community edition without authentication, so there isn’t much interesting information being output here.

And roles, if roles are being used, should be output with “SHOW ALL ROLES” … but mine just says “Unsupported administration command”
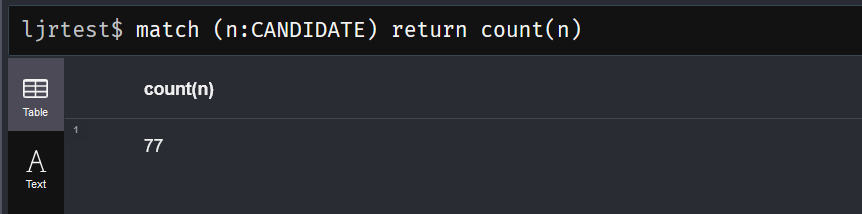
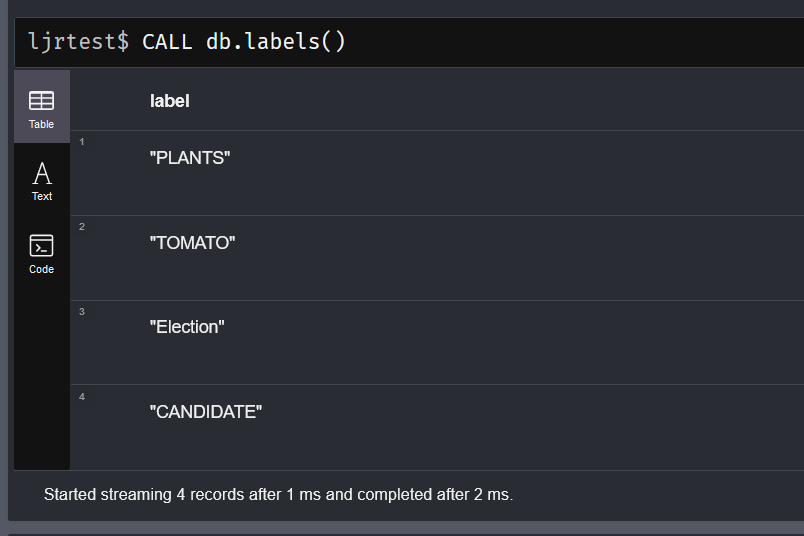
Once you know what databases you’ve got and who can log in and do stuff, we’d want to look at the data. There are some built-in functions that will help us out here. The db.labels() function will list the labels in the selected database.
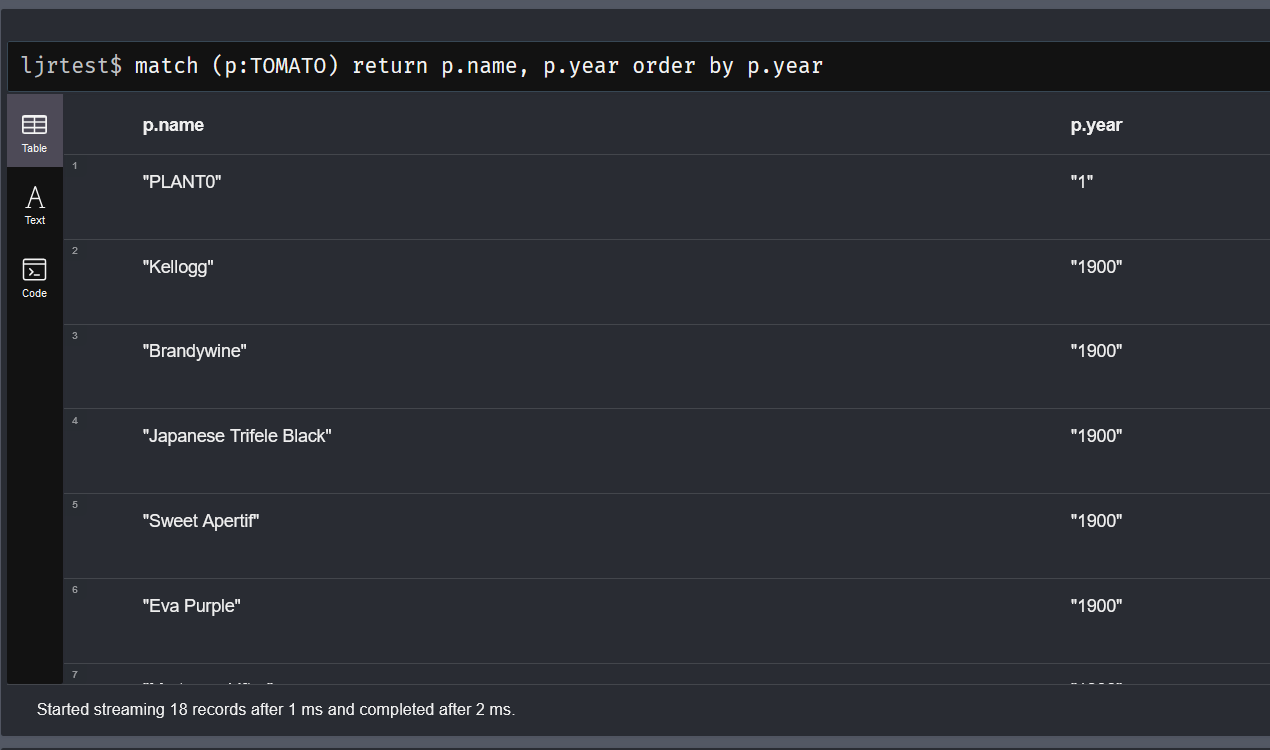
You can also return a distinct list of labels along with the count of nodes with that label:
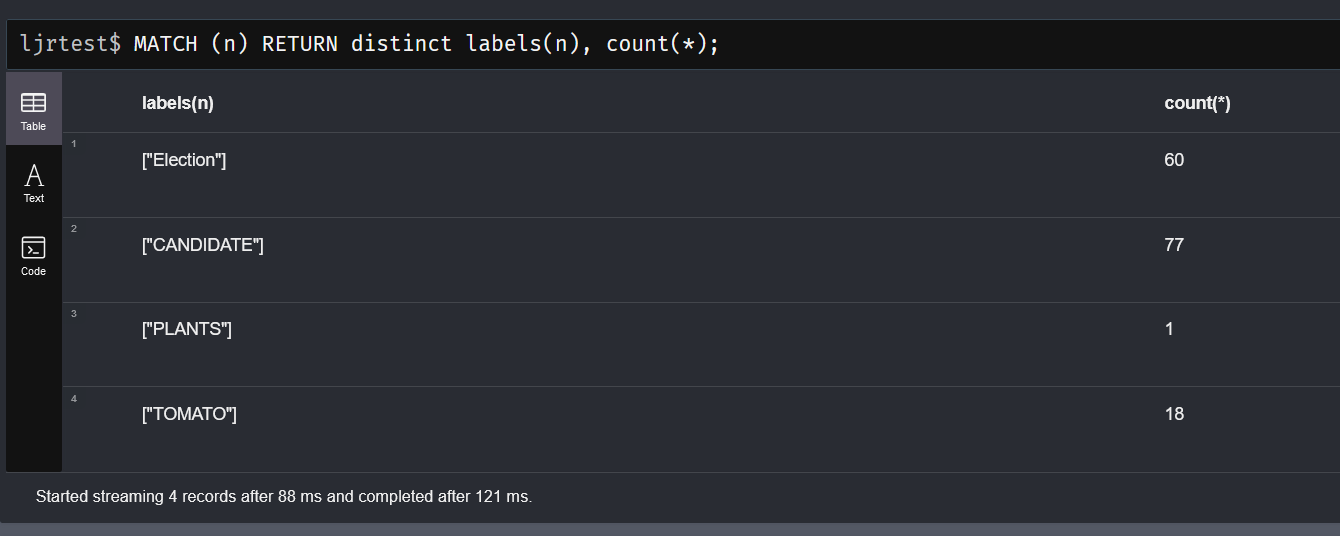
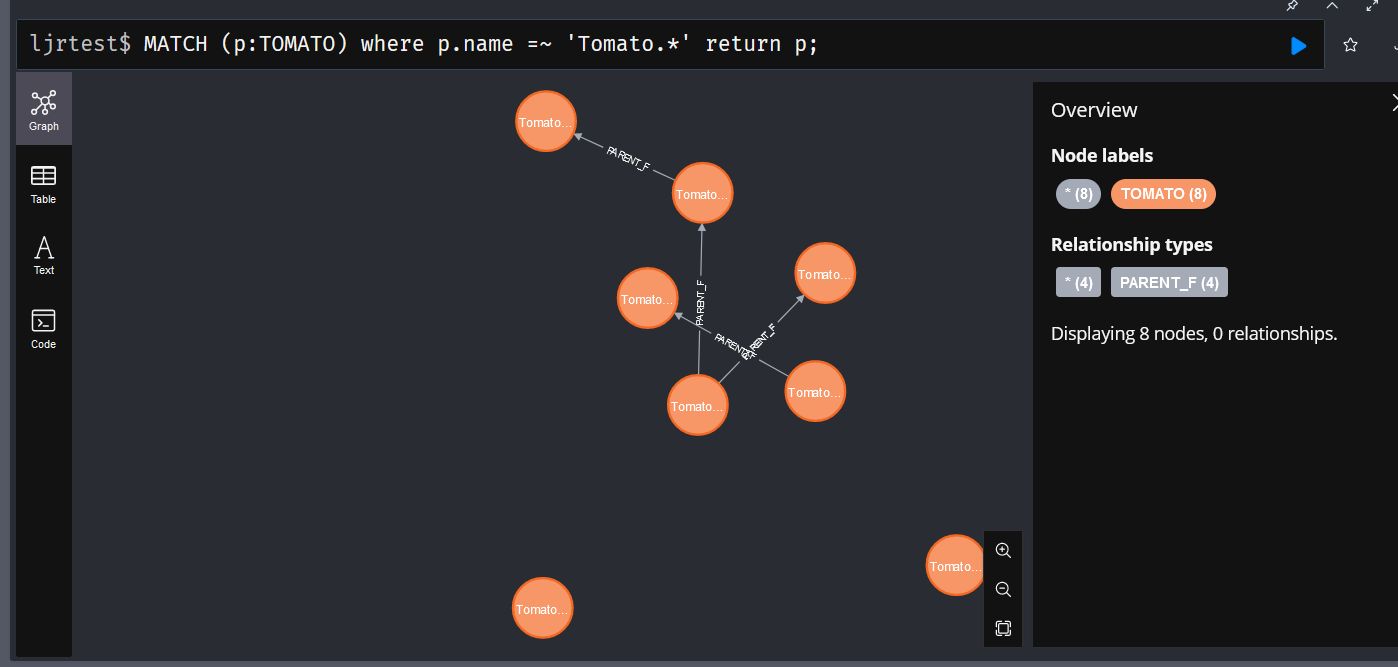
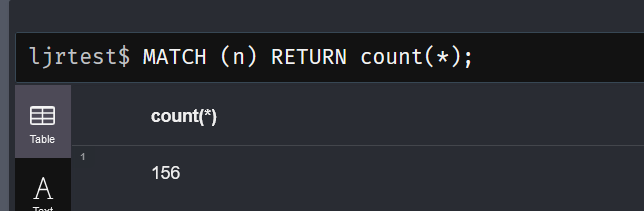
Since a node can have multiple, comparing that total with a count of nodes would give you an idea if there are many more labels than nodes. In my case, either view shows 156 … so I know there are few (if any) nodes with multiple labels.
To view the types of relationships defined in the selected database, use “CALL db.relationshipTypes()”
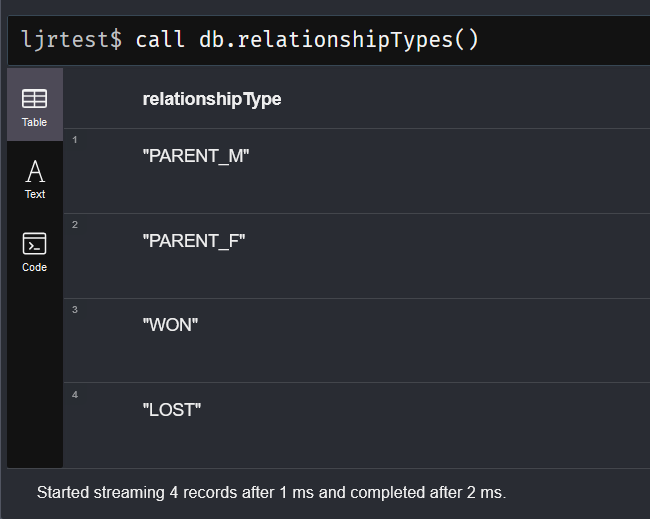
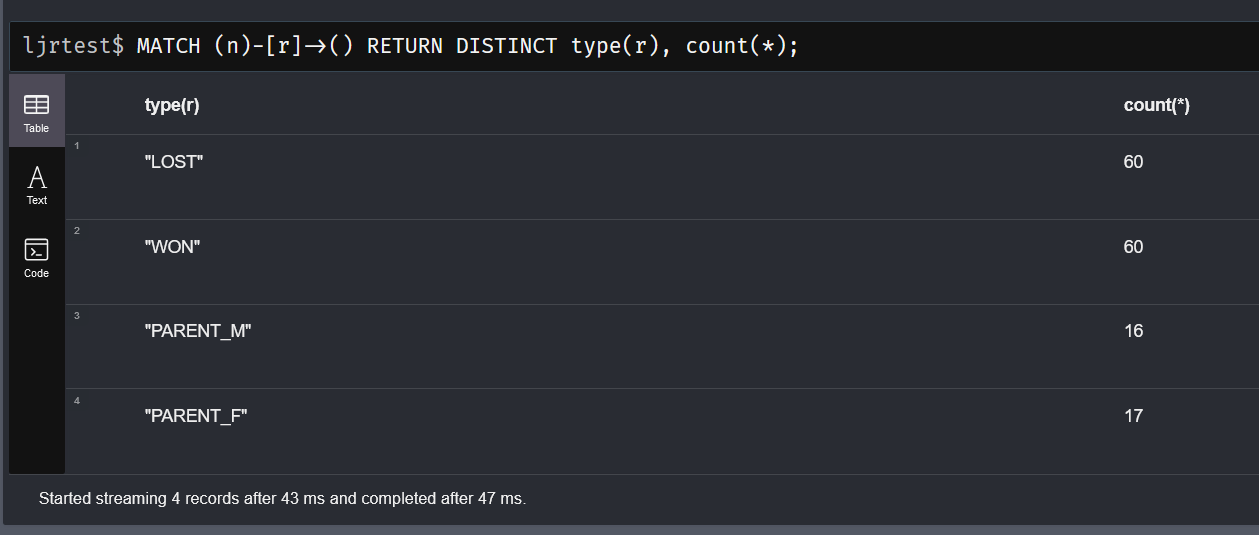
Similarly, you can return the relationship types along with counts
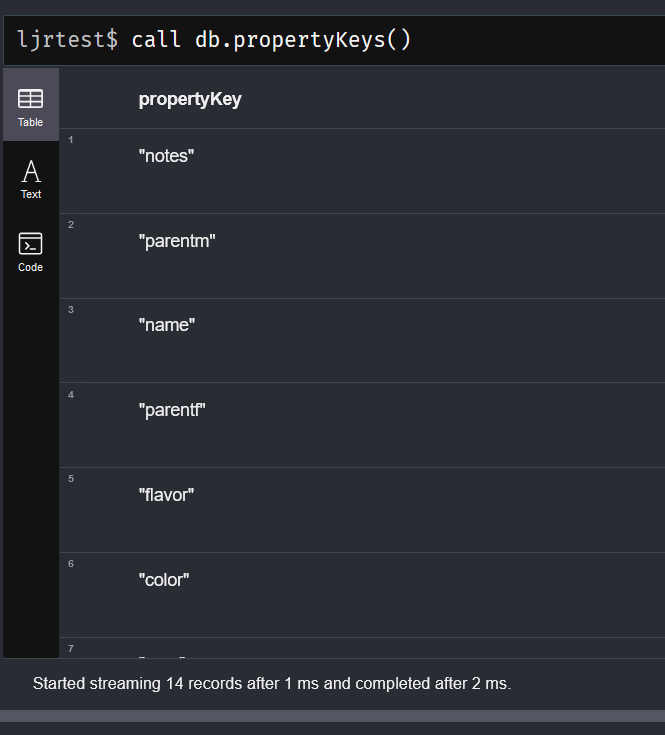
There is a function to list the property keys used within the data – interesting to note that keys that were used but the nodes using them were subsequently deleted … they still show up as property keys. Basically, anything that is there is on this list but some things on this list may not be there anymore. In this example, ‘parentm’ and ‘parentf’ were labels I used to build relationships programmatically.
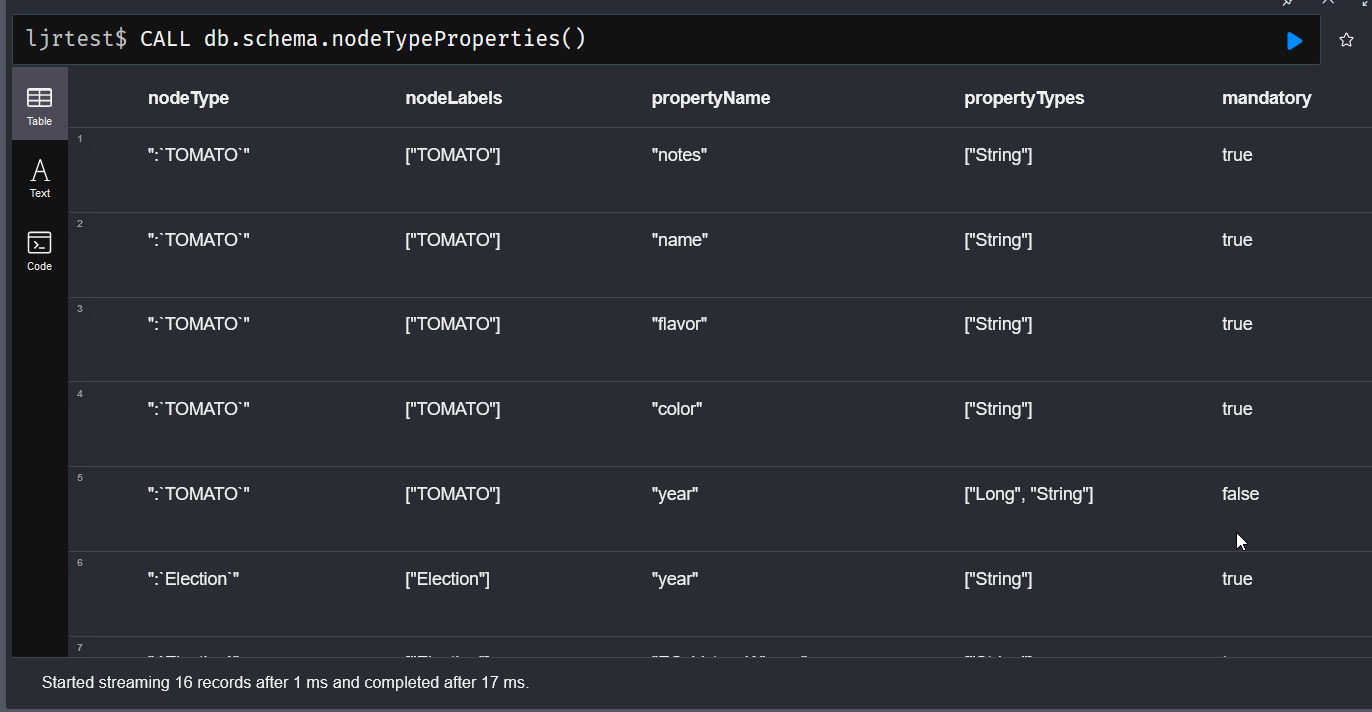
I’ve found db.schema.nodeTypeProperties to be more useful in this regard – it does not appear to list properties that are not in use, and the output includes field types
To see if there are any custom procedures or functions registered, look on the server(s). Use ps -efww to view the running command – there will be some folders listed after “-cp” … you could find procedures or plugins in any of those folders. In my case, the plugins are in /plugins

And the only “custom” things registered are the APOC and APOC-Extended jar’s