That didn’t take long — https://www.engadget.com/three-samsung-employees-reportedly-leaked-sensitive-data-to-chatgpt-190221114.html
Leaking data is obviously a big problem if the user base is “anyone with an internet connection”, but potentially not great even for an internal implementation of an AI chatbot.
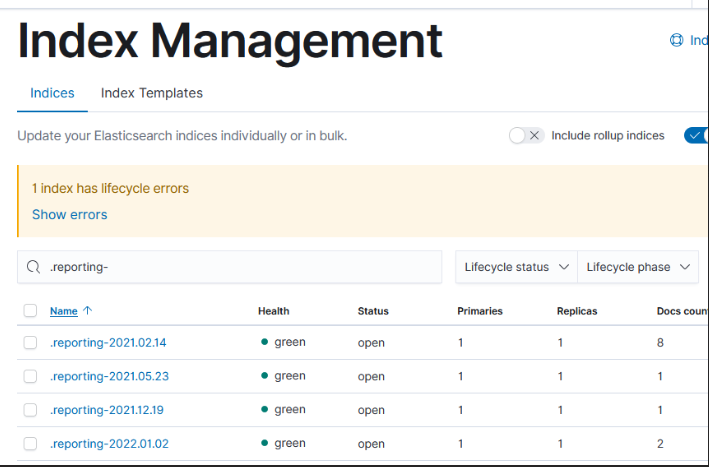
Content management platforms, in the early days, had a big problem with search because the indexing engine had super-user rights – so searching for “acquisition” would give you links that you couldn’t read. Even if the titles didn’t tell you anything (does “Project OPUS” or “Project Golden Falcon” have any meaning to you?), the dates & authors told you something (hey, there’s a bunch of new docs the C-levels are creating about acquisitions this past few weeks … sure that doesn’t mean anything!). Eventually any halfway decent content management platform understood permissions and at least attempts to filter results based on what you have permission to view.
AI is different, unfortunately in a way that makes implementing that type of security more difficult. Other than individualizing the trained AIs for each user (so info you feed in is only going to be reflected in your future results) or not training based on user input (only use stuff that’s openly readable already) … it would be rather challenging to filter an implementation so it knows stuff it’s been told but doesn’t convey that information to unauthorized individuals.