The following formula prints just the substring found before the first dash from the data in cell A2:
=LEFT(A2, FIND("-", A2) - 1)
The following formula prints just the substring found before the first dash from the data in cell A2:
=LEFT(A2, FIND("-", A2) - 1)
In case anyone else has been low-key bothered by the fact their Excel formula bar seems to have turned into a strange monospace font — you can change the default font around & that impacts the formula bar. Arial looks fairly reasonable for me. But there are lots of other fonts to chose from!
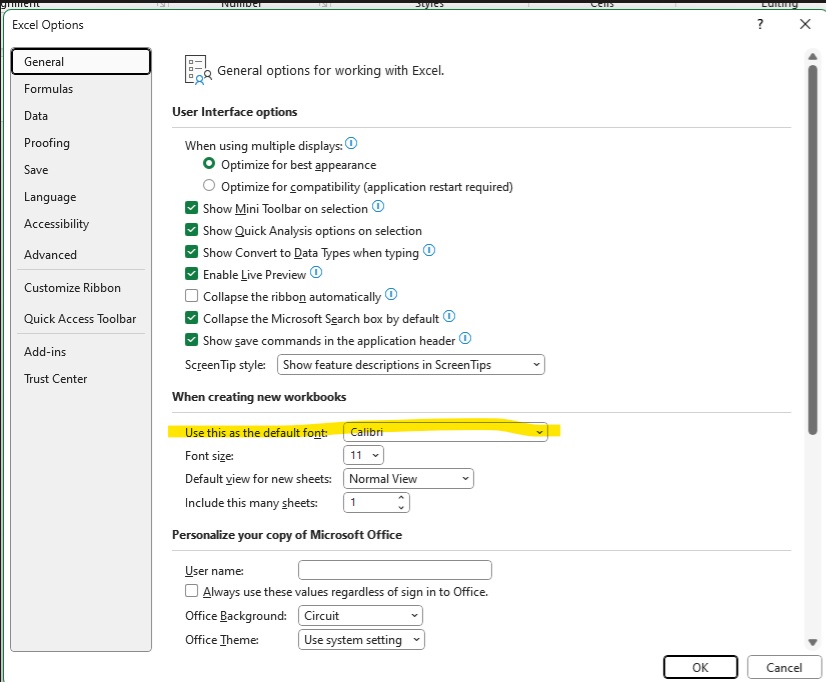
Also looks like a future update will include an option to not use monospace fonts for formulae … https://techcommunity.microsoft.com/blog/excelblog/excel’s-formula-bar-gets-a-new-look/3902462
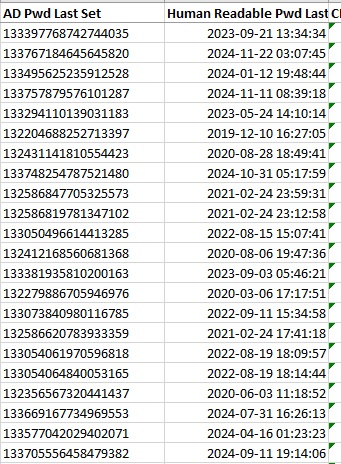
I’m doing “stuff” in AD again, and have again come across Microsoft’s wild “nanoseconds elapsed since 1601” reference time. AKA “Windows file time”. In previous experience, I was just looking to calculate deltas (how long since that password was set) so figuring out now, subtracting then, and converting nanoseconds elapsed into something a little less specific (days, for example) was fine. Today, though, I need to display a human readable date and time in Excel. Excel, which has its own peculiar way of storing date time values. Fortunately, I happened across a formula that works
=((C2-116444736000000000)/864000000000)+DATE(1970,1,1)
Voila!
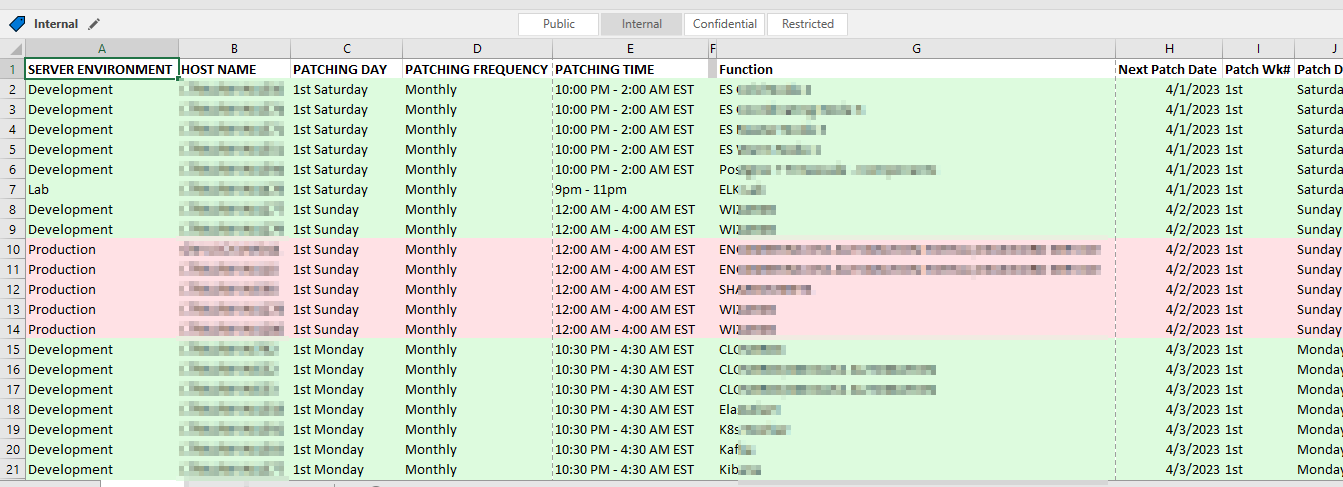
Our patching schedules are algorithmic – the 1st Tuesday of the month, the 3rd Wednesday of the month, etc. But that’s not particularly useful for notifying end users or for us to verify functionality after patching.
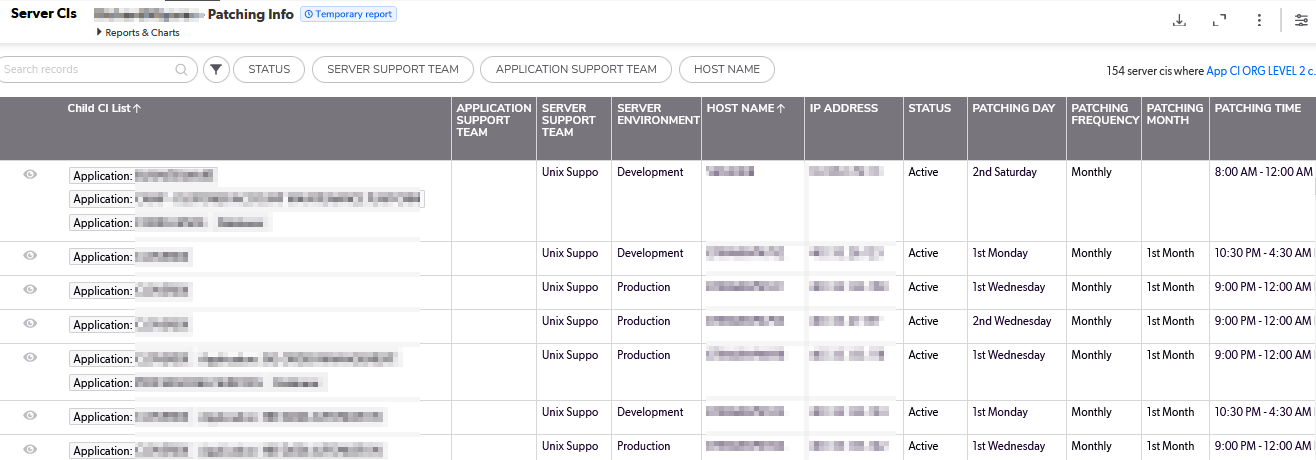
Long term, I think we can pull the source data from a database and create appointment items each month for whatever list of servers will be patched that month based on a relative date (so no one has to add new servers or remove decommissioned servers). But, short term? I really wanted a way to see what date a server would be patched. So I created a but of a convoluted spreadsheet to produce this information based on a list of servers and patching schedule patterns.
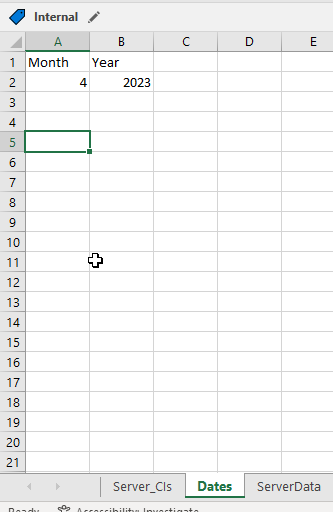
There are two “extra” tabs used – “Dates” used to say what month and year I want the patching dates for
And “ServerData” which provides a cross-reference between the server names and a useful description.
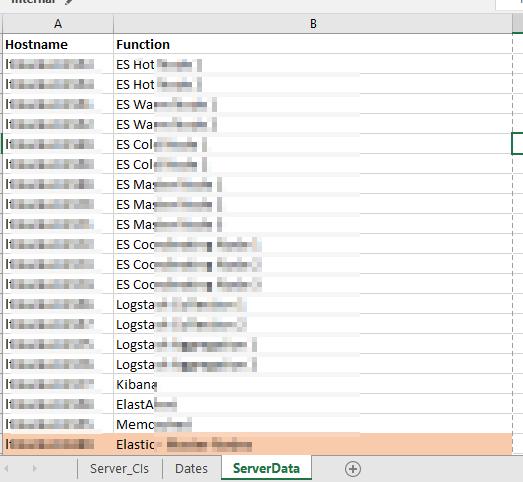
There are then a series of formulae used to add columns to our source data. First, the “Function” is populated in column G with a VLOOKUP =VLOOKUP(B2,ServerData!A:B,2,FALSE)
Columns I and J break the “1st Saturday” into the two components – week of month and day of week –
I =LEFT(C2,3)
J =RIGHT(C2,LEN(C2)-4)
Columns K and L then map these components into numeric values I can use in a formula:
K =IF(I2=”1st”,1,IF(I2=”2nd”,2,IF(I2=”3rd”,3,IF(I2=”4th”,4,”Unscheduled”))))
L =IF(J2=”Sunday”,1,IF(J2=”Monday”,2,IF(J2=”Tuesday”,3,IF(J2=”Wednesday”,4,IF(J2=”Thursday”,5,IF(J2=”Friday”,6,IF(J2=”Saturday”,7,”Unscheduled”)))))))
And finally a formula in column H that turns the week of month and day of week values into an actual date within the month and year on the “Dates” tab:
H =DATE(Dates!$B$2,Dates!$A$2,1+7*K2)-WEEKDAY(DATE(Dates!$B$2,Dates!$A$2,8-L2))
Voila – I have a spreadsheet that says we should expect to see this specific list of servers being patched tonight.
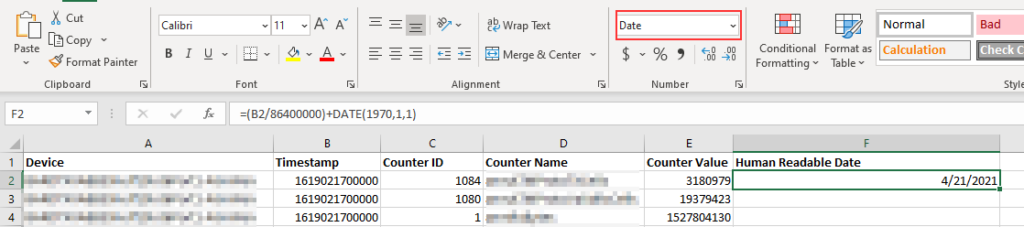
You can use the formula =(B2/86400)+DATE(1970,1,1) to convert a unix epoch time to a human readable date (or date time). In my case, I have the unix timestamp in microseconds so I’ve got to divide by 86400000. The value you get is a not-so-meaningful float … but that’s actually a date.

Select a date format to display the value as a date
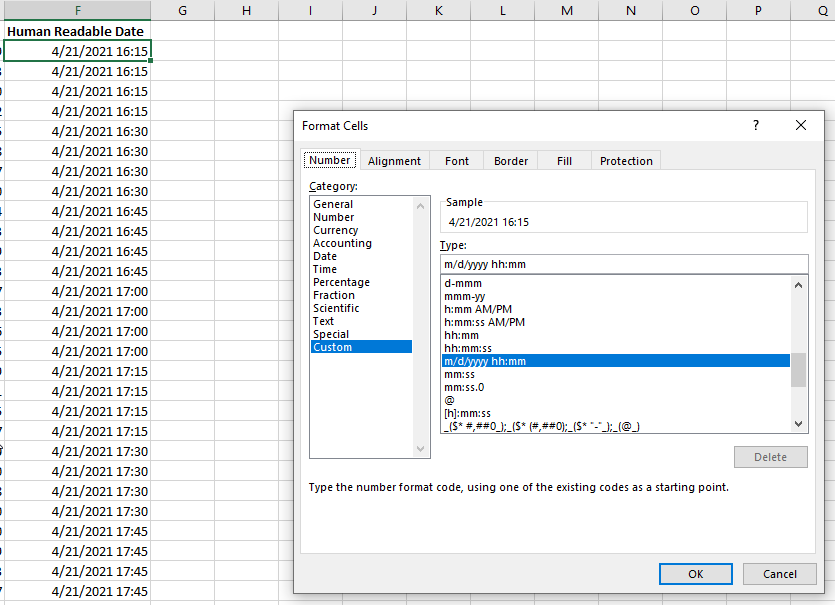
Or chose a custom format and use something like “m/d/yyyy hh:mm” to display a date and time.
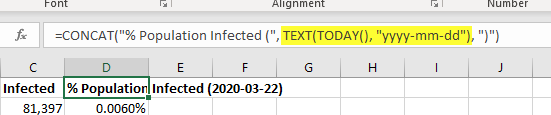
Here’s a trick to include the current date in an Excel string — especially useful if you want to include the current date on a graph without having to actually type the current date each time. If you just include TODAY(), you get the integer representation. Wrap TODAY() in TEXT() and supply the formatting you want (“yyyy-mm-dd” in my example). Voila, a date like 2020-03-22 instead of 43912.
I need to programmatically parse an Excel file where items are grouped with arbitrary group sizes. We don’t want the person filling out the spreadsheet to need to fill in a group # column … so I’m exploring ways to read cell formatting so something like color can be used to show the groups. Reading the formatting isn’t a straight-forward process, so I wondered if Excel could populate a group number cell based on the cell’s attributes.
While it is possible, it’s not a viable solution. The mechanism to access data about a cell cannot be accessed directly and, unfortunately, requires a macro-enabled workbook. The mechanism also requires the user to remember to update the spreadsheet calculations when they have finished colorizing the rows. While I won’t be using this approach in my current project … I thought I’d record what I did for future reference.
We need to define a ‘name’ for the function. On the “Formulas” tab, select “Name Manager”.
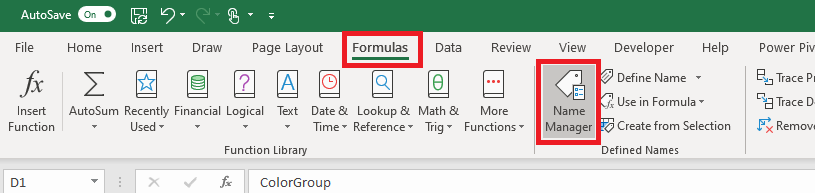
Select ‘New’
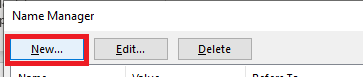
Provide a name – I am using getBackgroundColor – and put the following in the “refers to” section: =GET.CELL(63,INDIRECT(“rc”,FALSE))
Now we can use this name within the cell formula:
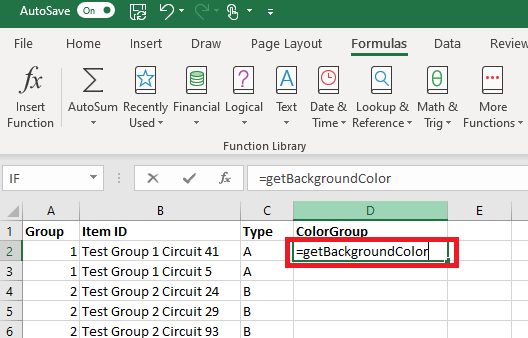
Select the rows for your first group and change the “fill color” of the row.
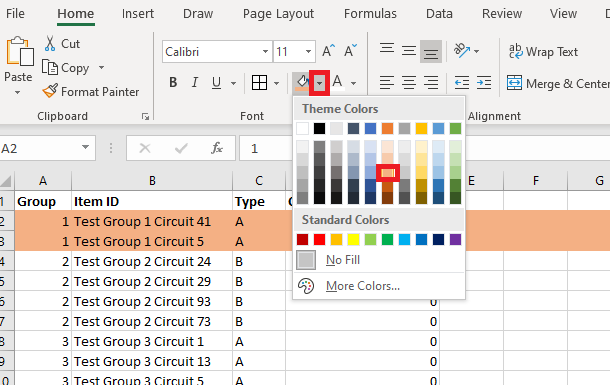
Repeat this process to colorize all of your groups – you can re-use a color as long as adjacent groups have different colors. Notice that the “ColorGroup” values do not change when you colorize your groups.
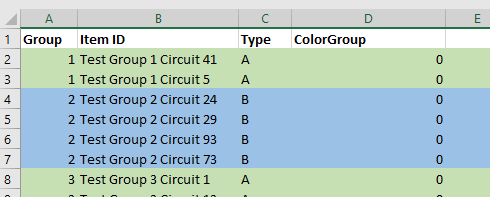
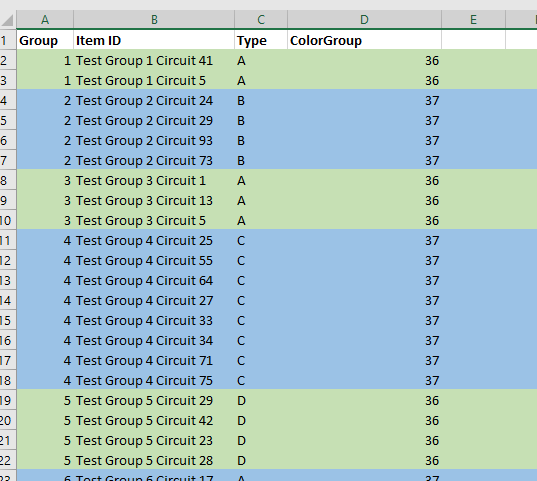
On the “Forumlas” tab, select “Calculate Now”

Now the colorized cells will have a non-zero value.
I hacked Box Spout to support column widths formatting, but wanted a quick way of adding appropriate column widths (yes, automatic width determination would be better … but I didn’t want to spend hours sorting that). Instead of wasting time on automatic column widths, I wrote a simple Excel code module to tell me the appropriate column widths. If your data width might vary, you can add some padding to the ReportColumnWidth function. My data, fortunately, is fixed width.
You will need to save your spreadsheet as a macro-enabled workbook (.xlsm). To add a function to Excel, hit Alt and F11. Select “Insert” => “Module” and paste in the following content and save.
Function iCeiling(iInput)
iCeiling = Int(iInput)
If iCeiling <> iInput Then
iCeiling = Int(iInput) + 1
End If
End Function
Function ReportColumnWidth(CellID As Range) As Double
Application.Volatile
ReportColumnWidth = iCeiling(CellID.ColumnWidth)
End Function
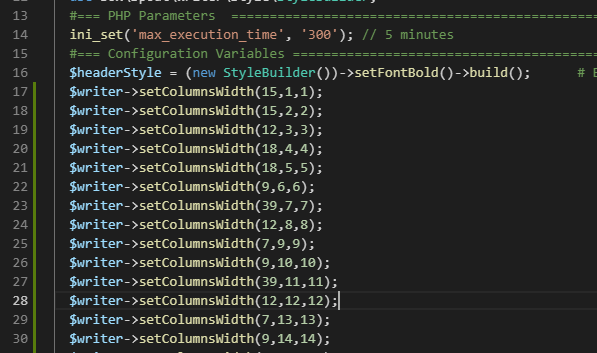
In Excel, use the ReportColumnWidth function to print the width of a column into a cell. This is my row #3.

In row #2, I have a counter that provides the row number for use in Box Spout. Row #4 creates the line needed to set the column width in my code using the concat function.
=CONCAT("$writer->setColumnsWidth(",A3,",",A2,",",A2,");")
Replacing the tab characters with newlines, I now have column widths set based on my data.
Remove duplicates is a quick way to obtain a unique list of records; every time the source data is updated, though, you’ve got to copy and ‘remove duplicates’ again. There’s a better way! Use Power Query to create a unique list that can be updated with a single click.
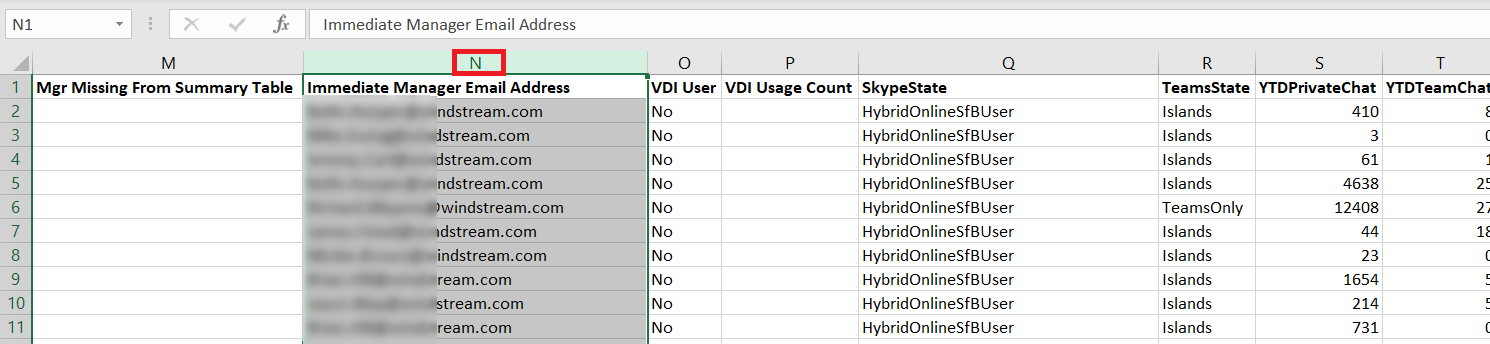
To use Power Query, first highlight the column containing the information for which you want a list of unique values.
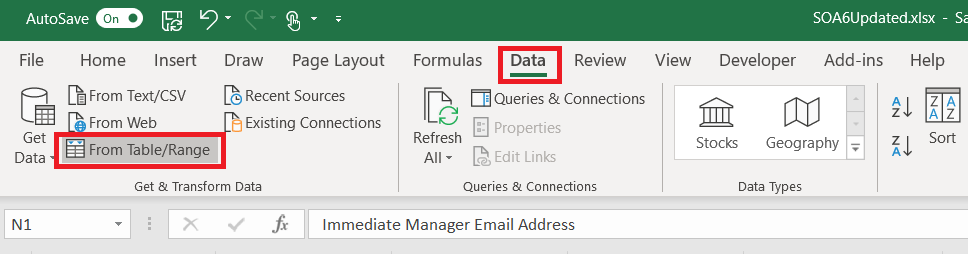
On the “Data” ribbon bar, select “From Table/Range”
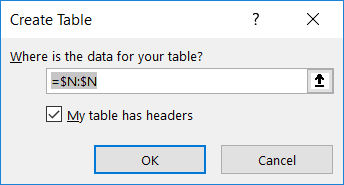
You’ll be asked to confirm where the source data is located – the highlighted selection should appear. Click “OK” to continue.
A new window will open – the Power Query Editor. On the “Home” ribbon bar, click on “Remove Rows” and select “Remove Duplicates”
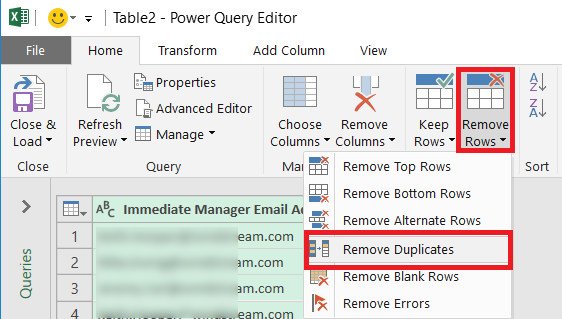
A unique list of values has been extracted in the Power Query editor – but you want to insert that data into your spreadsheet. Click the drop-down by “Close & Load” then select “Close & Load To …”
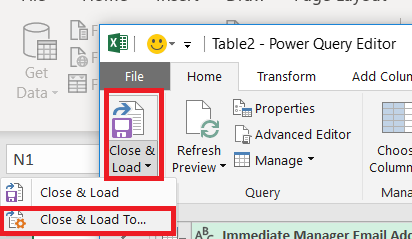
Now you can select where you want your list of unique values to appear – I am creating a table in an existing worksheet. Click “OK” to insert the unique list.
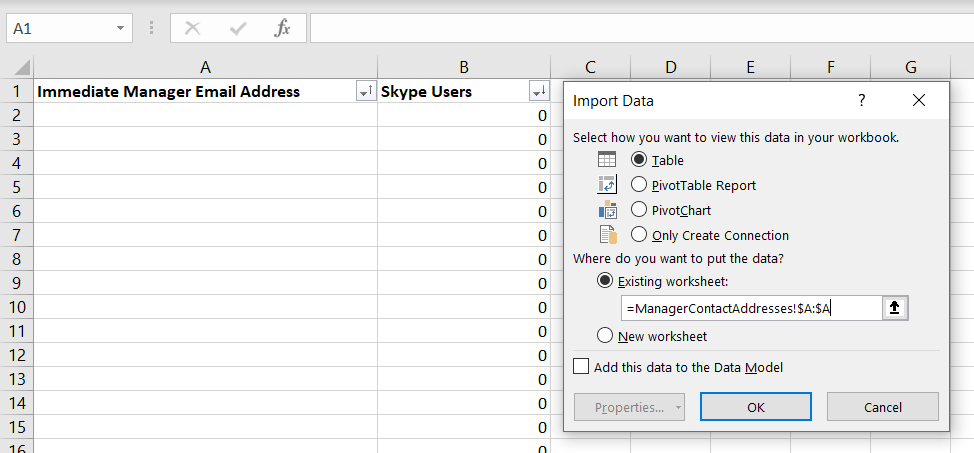
Voila, I now have a unique list.
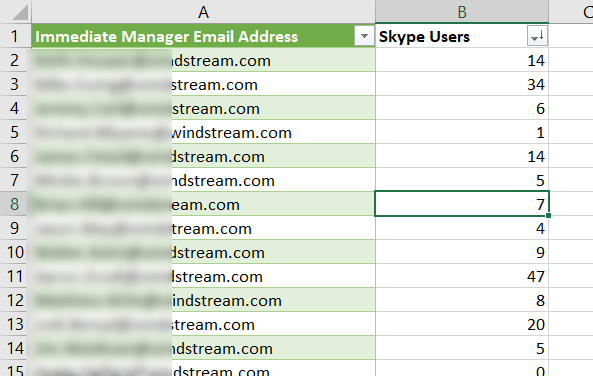
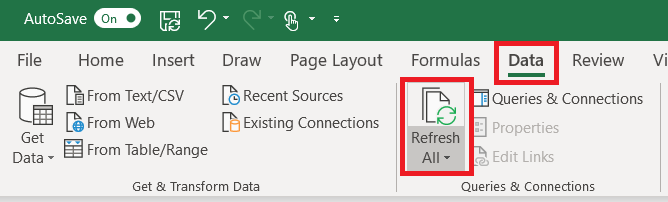
What happens when new records are added to my source data? The Power Query table does not automatically update as values are added to the source data. On the “Data” ribbon bar, click “Refresh All” to update the unique value list.
I mentioned yesterday that we’re creating groups based on the upper level manager through whom individuals report. Since my groups are based on the upper level managers, I need to be able to identify when a new individual pops into the list of upper level managers. Real upper level management doesn’t change frequently, but unfilled positions create gaps in the reporting structure. I call the manager before the gap the highest-ranking person in that vertical and that individual’s reporting subtree becomes a group.
Determining if values from one list appear in another list is easy in Microsoft Access – it’s an unmatched query. I’d rather not have to switch between the two programs, and I was certain an Excel formula could do the same thing. It can!
The formula is:
=IF(ISNA(VLOOKUP(H2,SOA6MgrSummary!A:A,1,FALSE)),”Not in Manager Summary”,””)
And it does flag any manager from column H that does not appear in my list of upper level managers.

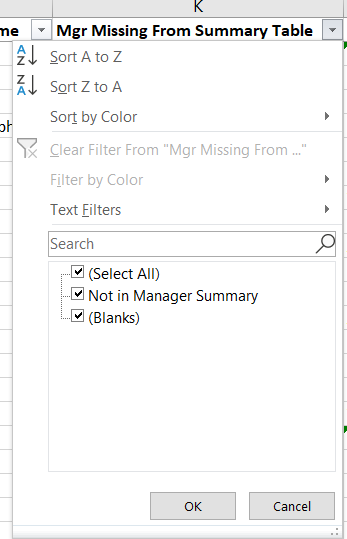
I am also able to filter my spreadsheet to display only records where the upper level manager does not appear in my summary table.
What is my formula doing? It is a combination of three functions
=IF(ISNA(VLOOKUP(H2,SOA6MgrSummary!A:A,1,FALSE)),”Not in Manager Summary”,””)
It starts with the IF function – a logical comparison – which is used as if(Test,ResultIfTestIsTrue, ResultIfTestIsFalse).
If the test is true, “Not in Manager Summary” will be put into the cell. If the test is false, nothing (“”) will be put into the cell.
The test itself is two functions. I’ve documented the VLOOKUP function previously, but briefly it searches a range of data for a specific value. If the value is found, it returns something. If the value isn’t found, it returns N/A.
In conjunction with the VLOOKUP, I am using the ISNA function. This function is a logic test – it returns TRUE when the value is N/A and FALSE otherwise.
So my formula says “Look for the value of cell H2 in column A of the SOA6MgrSummary tab. If the result is N/A, put ‘Not in Manager Summary’ in this cell, otherwise leave this cell empty”.