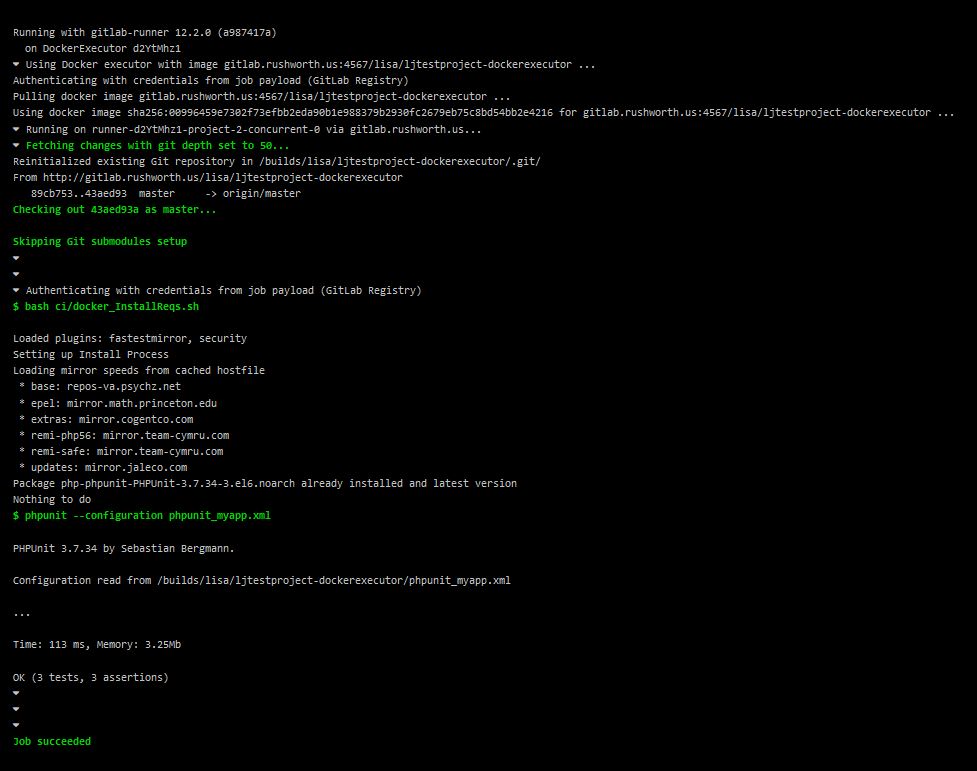
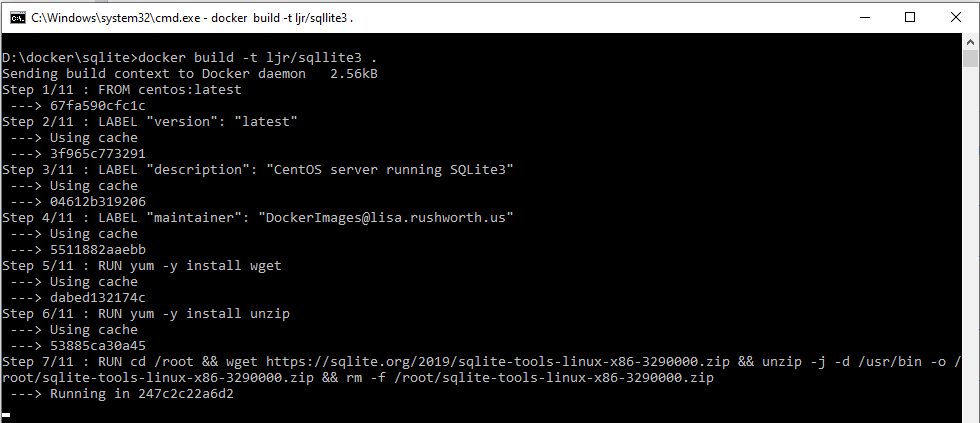
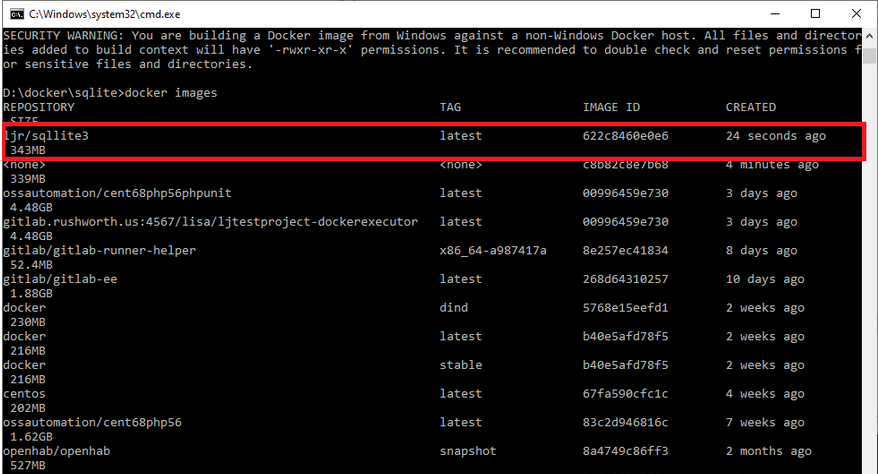
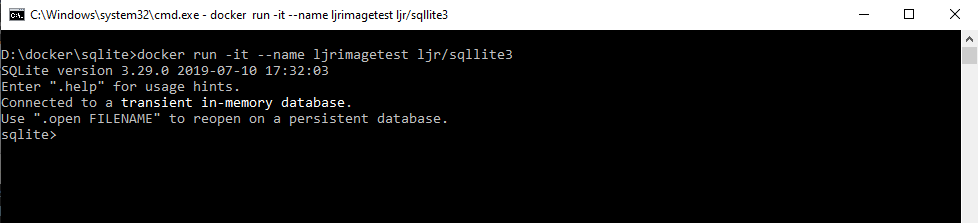
I’ve been trying to set up a Docker container running an older CentOS, Apache, and PHP version as a sandbox for work. This would allow me to update code on my local computer, test changes, and then pull the changes to the development server for UAT testing. Setting up the base container was easy enough — installed a VM, tar’d off the system, and imported it as a Docker image. There’s a lot of optimization that could/should be done, but I was aiming for proof of concept at this stage.
I am using bind mounts for the website configuration and code — the website conf file in conf.d, the SSL certificates, and the vhtml folder which houses the web code. This means I can tweak the site config & code in my IDE, reload Apache in Docker, and validate my changes. It worked great until I connected to the company VPN. Attempting to access the mounted data just hangs. Nothing. Drop the VPN, and the files are there again.
There are two problems — firstly, the default VPN configuration does not allow access to local network resources. And, it seems, the Docker NAT is a local network resource. We use Cisco AnyConnect. In the settings, I checked off “Allow local (LAN) access when using VPN (if configured)”. Note the if configured — the server-side settings need to allow use of local resources when connected via VPN. Fortunately, people with WiFi printers complained about having to disconnect the VPN every time they wanted to print something; and accessing local resources is permitted in our profile.
Unfortunately, I still couldn’t access files on my mount points. Docker Desktop shared out my drive, and the server network mounts the CIFS share. With my domain credentials. An Active Directory domain which is most certainly not registered in the VPN DNS servers.
[root@5542506m1a5e /]# mount
overlay on / type overlay (rw,relatime,lowerdir=/var/lib/docker/overlay2/l/QMCCTMGPBHQFW66ARPWHSQMWQL:/var/lib/docker/overlay2/l/IQ2YIH47ZXTN55PGH3BWUKFPTT,upperdir=/var/lib/docker/overlay2/d072c94532976a4196174751c57359139501739001e7b9d50de59041c768a307/diff,workdir=/var/lib/docker/overlay2/d072c94532976a4196174751c57359139501739001e7b9d50de59041c768a307/work)
proc on /proc type proc (rw,nosuid,nodev,noexec,relatime)
...
//10.0.75.1/D on /etc/httpd/certs type cifs (rw,relatime,vers=3.02,sec=ntlmsspi,cache=strict,username=myuid,domain=mydomain,uid=0,noforceuid,gid=0,noforcegid,addr=10.0.75.1,file_mode=0755,dir_mode=0777,iocharset=utf8,nounix,serverino,mapposix,nobrl,mfsymlinks,noperm,rsize=1048576,wsize=1048576,echo_interval=60,actimeo=1)
...
tmpfs on /sys/firmware type tmpfs (ro,relatime)
To use the share when connected via the VPN, I needed to use the credentials of a local account here. Beyond creating a local administator-level account, you may need to add read/write permissions for that new account to your %userprofile% directory — inheritence is generally disabled & only the individual user has access to the folder.
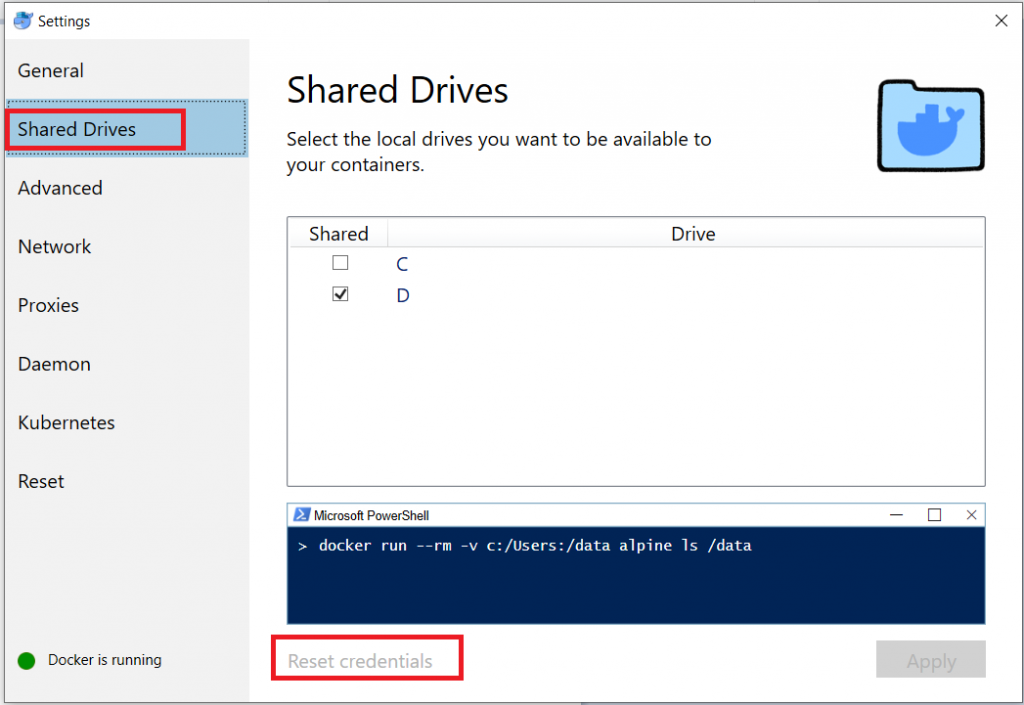
Once there’s a local account set up to work, you’ve got to tell Docker to use it. In the settings, select “Shared Drives”. Use “Reset credentials” to open a prompt for the logon credentials that will be used to mount the shared volume.
 o
o
Start the Docker container, VPN into the company network, and I’ve got a fully functional sandbox in a Docker container.