Analyzer Components
Character filters are the first component of an analyzer. They can remove unwanted characters – this could be html tags (“char_filter”: [“html_strip”]) or some custom replacement – or change character(s) into other character(s). Output from the character filter is passed to the tokenizer.
The tokenizer breaks the string out into individual components (tokens). A commonly used tokenizer is the whitespace tokenizer which uses whitespace characters as the token delimiter. For CSV data, you could build a custom pattern tokenizer with “,” as the delimiter.
Then token filters removes anything deemed unnecessary. The standard token filter applies a lower-case function too – so NOW, Now, and now all produce the same token.
Testing an analyzer
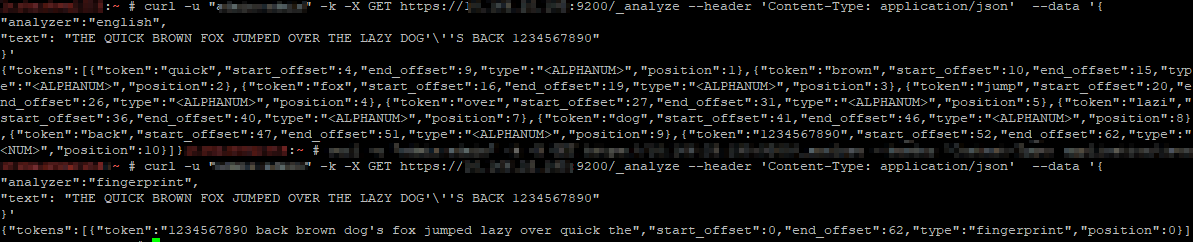
You can one-off analyze a string using any of the
curl -u “admin:admin” -k -X GET https://localhost:9200/_analyze –header ‘Content-Type: application/json’ –data ‘
“analyzer”:”standard”,
“text”: “THE QUICK BROWN FOX JUMPED OVER THE LAZY DOG’\”S BACK 1234567890″
}’

Specifying different analyzers produces different tokens
It’s even possible to define a custom analyzer in an index – you’ll see this in the index configuration. Adding character mappings to a custom filter – the example used in Elastic’s documentation maps Arabic numbers to their European counterparts – might be a useful tool in our implementation. One of the examples is turning ASCII emoticons into emotional descriptors (_happy_, _sad_, _crying_, _raspberry_, etc) that would be useful in analyzing customer communications. In log processing, we might want to map phrases into commonly used abbreviations (not a real-world example, but if programmatic input spelled out “self-contained breathing apparatus”, I expect most people would still search for SCBA if they wanted to see how frequently SCBA tanks were used for call-outs). It will be interesting to see how frequently programmatic input doesn’t line up with user expectations to see if character mappings will be beneficial.
In addition to testing individual analyzers, you can test the analyzer associated to an index – instead of using the /_analyze endpoint, use the /indexname/_analyze endpoint.