SysInternals used to produce a suite of tools for working with Microsoft Windows systems — the company appears to have been acquired by Microsoft, and the tools continue to be developed. I used PSKill and PSExec to automate a lot of system administration tasks. ProcessMonitor is like truss/strace for Windows. Unlike the HFS standard, Windows files end up all over the place (plus info is stashed in the registry). Sometimes applications or services fall over for no reason. Process monitor reports out
When you open procmon, you can build filters to exclude uninteresting operations — there’s a default set of exclusions (no need to log out what procmon is doing!)
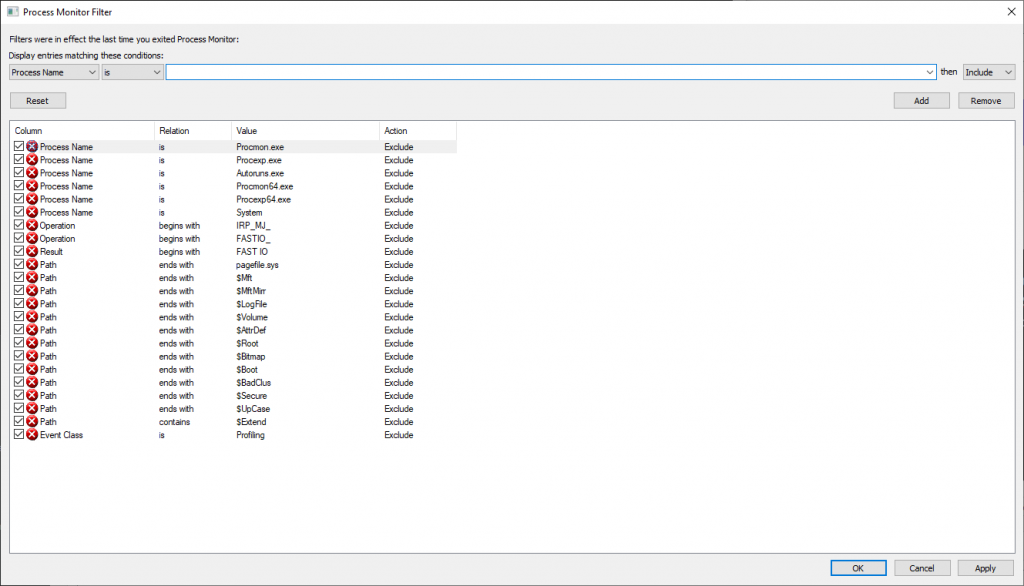
Adding exclusions for specific process names can eliminate a lot of I/O — I was looking to troubleshoot a problem on a Domain Controller that had nothing to do with AD specifically, so excluding activity by lsass.exe significantly reduced the amount of data being logged. If I’m using a browser to troubleshoot the problem, I’ll exclude the firefox.exe or chrome.exe binary too.
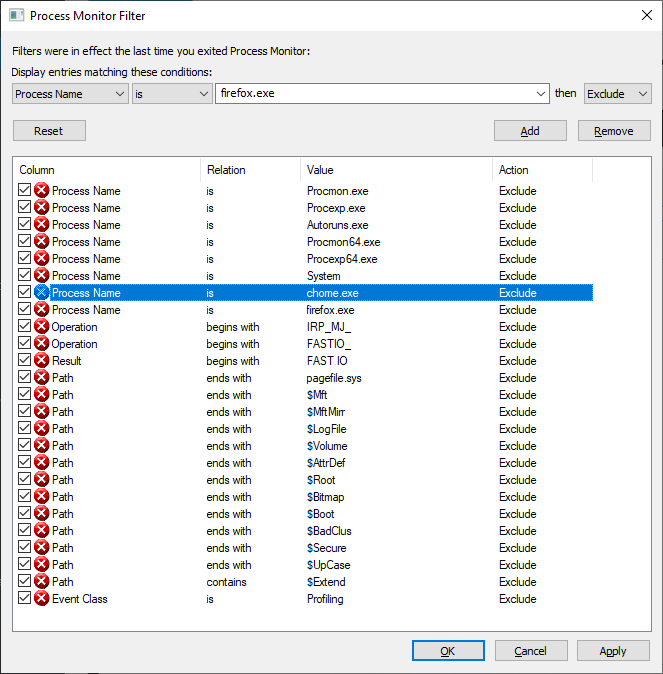
From the filter screen, click “OK” to begin grabbing data. The easiest thing I’ve found to do is stop capturing data when the program opens (use ctrl-a followed by ctrl-x to clear the already logged stuff). Stage whatever you want to log, use ctrl-e to start capturing. Perform the actions you want to log, return to procmon and use ctrl-e to stop again.
You’ll see reads (and writes) against the registry, including the specific keys. Network operations. File reads and writes. In the “Result” and “Detail” column, you can determine if the operation was successful. There are a lot of expected not found failures — I see these in truss/strace logs too, programs try a bunch of different things and one of them needs to work.
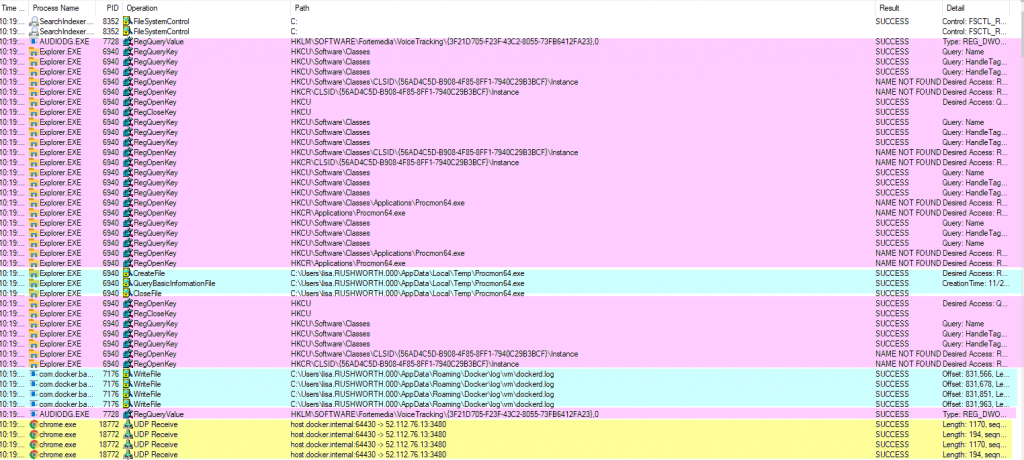
I’ve had programs using a specific, undocumented file for a critical operation — like the service would fail to start because the file didn’t exist. And seeing the path and file open failure allowed me to create that needed file and run my service. I’ve wanted to find out where a program stashes data, and procmon makes that easy to identify.