Quick command to list the db links available from a database:
SELECT DB_LINK, USERNAME, HOST FROM ALL_DB_LINKS ;
Quick command to list the db links available from a database:
SELECT DB_LINK, USERNAME, HOST FROM ALL_DB_LINKS ;
This vulnerability occurs when you accept user input and then use that input in a SQL query. The basic remediation is to use oci_bind_by_name to bind variables into placeholders.
The simplest case is a query with an equivalence clause.
The code:
$strQuery = "SELECT DISTINCT EXCHANGE_CARRIER_CIRCUIT_ID, CIRCUIT_DESIGN_ID FROM circuit$strDBLink WHERE EXCHANGE_CARRIER_CIRCUIT_ID = '$strECCKT' ORDER BY CIRCUIT_DESIGN_ID"; $stmt = oci_parse($kpiprd_conn, $strQuery); oci_set_prefetch($stmt, 300); oci_execute($stmt);
Becomes:
$strQuery = "SELECT DISTINCT EXCHANGE_CARRIER_CIRCUIT_ID, CIRCUIT_DESIGN_ID FROM circuit$strDBLink WHERE EXCHANGE_CARRIER_CIRCUIT_ID IN :ecckt ORDER BY CIRCUIT_DESIGN_ID"; $stmt = oci_parse($kpiprd_conn, $strQuery); oci_bind_by_name($stmt, ':ecckt', $strECCKT); oci_set_prefetch($stmt, 300); oci_execute($stmt);
The same placeholder can be used with the like query. Use “select something from table where columnname like :placeholdername” followed by an oci_bind_by_name($stmt, “:placeholdername”, $strPlaceholderVariable).
– is a little tricker. You could iterate through the array of values and build :placeholder1, :placeholder2, …, :placeholdern and then iterate through the array of values again to bind each value to its corresponding placeholder. A cleaner approach is to use an Oracle collection ($coll in this example) and binding the collection to a single placeholder.
$arrayCircuitNames = array('L101 /T1 /ELYROHU0012/ELYROHXA32C','111 /ST01 /CHMPILCPF01/CHMPILCPHH3','C102 /OC12 /PHLAPAFG-19/PHLAPAFGW22')
$strQuery = "SELECT CIRCUIT_DESIGN_ID, EXCHANGE_CARRIER_CIRCUIT_ID FROM circuit$strDBLink WHERE EXCHANGE_CARRIER_CIRCUIT_ID in (SELECT column_value FROM table(:myIds))"; $stmt = oci_parse($kpiprd_conn, $strQuery);
$coll = oci_new_collection($kpiprd_conn, 'ODCIVARCHAR2LIST','SYS');
foreach ($arrayCircuitNames as $key) {
$coll->append($key);
}
oci_bind_by_name($stmt, ':myIds', $coll, -1, OCI_B_NTY);
oci_set_prefetch($stmt, 300);
oci_execute($stmt);
Queries with an OR’d group of LIKE clauses can be handled in a similar fashion – either iterate through the array twice or create a collection with strings that include the wildcard characters, then bind that collection to a single placeholder. Create a semi-join using an EXISTS predicate
$arrayLocs = array('ERIEPAXE%', 'HNCKOHXA%', 'LTRKARXK%');
$strQuery = "select location_id, clli_code from network_location$strDBLink where exists (select 1 from TABLE(:likelocs) where clli_code like column_value) order by clli_code";
$stmt = oci_parse($kpiprd_conn, $strQuery);
$coll = oci_new_collection($kpiprd_conn, 'ODCIVARCHAR2LIST','SYS');
foreach ($arrayLocs as $strLocation) {
$coll->append($strLocation);
}
oci_bind_by_name($stmt, ':likelocs', $coll, -1, OCI_B_NTY);
oci_execute($stmt);
Queries where values are selected from DUAL – In some of my recursive queries, I need to include the original input in the result set (particularly, this query finds all equipment mounted under a specific equipment ID – I want to include the input equipment ID as well). Having a bunch of ‘select 12345 from dual’ is fine until I need to use placeholders. This is another place where the collection can be leveraged:
select column_value equipment_id from TABLE(sys.ODCIVARCHAR2LIST('12345CDE', '23456BCD', '34567ABC') );
Adds each of the values to my result set.
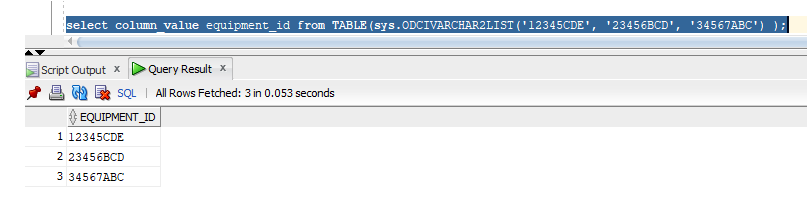
Which means I can use a query like “select column_value as equipment_id from TABLE(:myIDs)” and bind the collection to :myIDs.
The company for which I work signed a contract with some vendor for cloud-based static code analysis. We ran our biggest project through it and saw just shy of ten thousand vulnerabilities. Now … when an application sits out on the Internet, I get that a million people are going to try to exploit whatever they can in order to compromise your site. When the app is only available internally? I fully support firing anyone who plays hacker against their employer’s tools. When a tool is an automation that no one can access outside of the local host? Lazy, insecure code isn’t anywhere near the same problem it is for user-accessible sites. But the policy is the policy, so any code that gets deployed needs to pass the scan — which means no vulnerabilities identified.
Some vulnerabilities have obvious solutions — SQL injection is one. It’s a commonly known problem — a techy joke is that you’ll name your kid “SomeName’;DROP TABLE STUDENTS; … and most database platforms support parameterized statements to mitigate the vulnerability.
Some vulnerabilities are really a “don’t do that!” problem — as an example, we were updating the server and had a page with info(); on it. Don’t do that! I had some error_log lines that output user info that would be called when the process failed (“Failed to add ecckt $iCircuitID to work order $iWorkOrderID for user $strUserID with $curlError from the web server and $curlRepsonse from the web service”). I liked having the log in place so, when a user rang up with a problem, I had the info available to see what went wrong. The expedient thing to do here, though, was just comment those error_log lines out. I can uncomment the line and have the user try it again. Then checkout back to the commented out iteration of the file when we’re done troubleshooting.
Some, though … static code analysis tools don’t always understand that a problem is sorted when the solution doesn’t match one of their list of ‘approved’ methods. I liken this to early MS MCSE tests — there was a pseudo-GUI that asked you to share out a printer from a server. You had to click the exact right series of places in the pseudo-GUI to answer the question correctly. Shortcut keys were not implemented. Command line solutions were wrong.
So I’ve started documenting the solutions we find that pass the Fortify on Demand scan for everything identified in our scans — hopefully letting the next teams that use the static scanner avoid the trial-and-error we’ve gone through to find an acceptable solution.
I’m still retrofitting a bunch of SQL queries to use bind_by_name and came across a strange scenario. I created a recursive query (STARTS WITH / CONNECT BY PRIOR) but I needed to grab the original value too. The quickest way to accomplish this was to union in something like “select 12345CDE as equipment_id from dual”. But the only way to get a bunch of these original values grafted onto the result set is to iterate through the array once to build my :placeholder1, :placeholder2, …, placeholderN placeholders and then iterate through the array again to bind each placeholder to its proper value.
I’ve been working with Oracle collections for LIKE and IN queries, and thought I could use a table that only exists within the query to glom the entire array into a single placeholder. It works! A query like
select column_value equipment_id from TABLE(sys.ODCIVARCHAR2LIST('12345CDE', '23456BCD', '34567ABC') );
Adds each of the values to my result set.
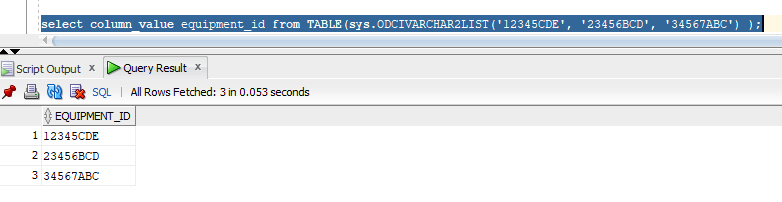
Which means I can use a query like “select column_value as equipment_id from TABLE(:myIDs)” and bind the collection to :myIDs.
I’ve been retrofitting a lot of PHP/SQL queries to use oci_bind_by_name recently. When using “IN” clauses, you can iterate through your array twice, but it’s an inefficient approach.
// Build the query string with a bunch of placeholders
$strQuery = "select Col1, Col2, Col3 from TableName where ColName IN (";
for($i=0; $i < count($array); $i++){
if($i > 0){
$strQuery = $strQuery . ", ";
}
$strQuery = $strQuery . ":bindvar" . $i;
}
$strQuery = $strQuery . ")";
...
// Then bind each placeholder to something
for($i=0; $i < count($array); $i++){
oci_bind_by_name($stmt, ":bindvar".$i, $array[$i]);
}
Building a table from the array data and using an Oracle collection object creates cleaner code and avoids a second iteration of the array:
$strQuery = "SELECT indexID, objName FROM table WHERE objName in (SELECT column_value FROM table(:myIds))";
$stmt = oci_parse($conn, $strQuery);
$coll = oci_new_collection($kpiprd_conn, 'ODCIVARCHAR2LIST','SYS');
foreach ($arrayValues as $strValue) {
$coll->append($strValue);
}
oci_bind_by_name($stmt, ':myIds', $coll, -1, OCI_B_NTY);
oci_set_prefetch($stmt, 300);
oci_execute($stmt);
A simple like clause is quite straight-forward
$strNameLikeString = "SomeName%";
$strQuery = "SELECT ds_dvrsty_set_nm from ds_dvrsty_set WHERE ds_dvrsty_set_nm LIKE :divsetnm ORDER BY ds_dvrsty_set_nm DESC fetch first 1 row only";
$stmt = oci_parse($connDB, $strQuery);
oci_bind_by_name($stmt, ":divsetnm", $strNameLikeString);
oci_set_prefetch($stmt, 300);
oci_execute($stmt);
But what about an array of inputs essentially reproducing the LIKE ANY predicate in PostgreSQL? There’s not a direct equivalent in Oracle, and iterating through the array twice to build out a query WHERE (Field1 LIKE ‘Thing1%’ OR Field1 LIKE ‘Thing2%’ OR Field1 LIKE ‘Thing3%’) is undesirable. The with EXISTS allows me to create a LIKE ANY type query and only iterate through my array once to bind variables to placeholders using the same collection approach as was used with the IN clause.
$arrayLocs = array('ERIEPAXE%', 'HNCKOHXA%', 'LTRKARXK%');
$strQuery = "SELECT location_id, clli_code FROM network_location WHERE EXISTS (select 1 FROM TABLE(:likelocs) WHERE clli_code LIKE column_value)";
$stmt = oci_parse($connDB, $strQuery);
$coll = oci_new_collection($connDB, 'ODCIVARCHAR2LIST','SYS');
foreach ($arrayLocs as $strLocation) {
$coll->append($strLocation);
}
oci_bind_by_name($stmt, ':likelocs', $coll, -1, OCI_B_NTY);
oci_execute($stmt);
print "<table>\n";
print "<tr><th>Loc ID</th><th>CLLI</th></tr>\n";
while ($row = oci_fetch_array($stmt, OCI_ASSOC+OCI_RETURN_NULLS)) {
print "<tr><td>" . $row['LOCATION_ID'] . "</td><td>" . $row['CLLI_CODE'] . "</td></tr>\n";
}
print "</table>\n";
There are many different collection types in Oracle which can be used with oci_new_collection. A full list of the system collection types can be queried from the database.
SELECT * FROM SYS.ALL_TYPES WHERE TYPECODE = 'COLLECTION' and OWNER = 'SYS';
I have been using LISTAGG to group a bunch of records together to be presented in a single HTML table cell. Problem is LISTAGG doesn’t do anything with null field values. As such, the data doesn’t line up across columns. The three ID values have two string values, which basically get centered in the cell. You cannot tell which ID value goes to which name value.

By adding a concatenation to the LISTAGG value, something will be included in the result set even when the record value is null.
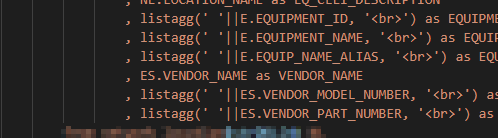
Voila — records line up and I can tell the first ID doesn’t have an associated string value.

I needed to add a few HTML-rendered spaces to a LISTAGG … which meant I needed to figure out a way of getting an ampersand into the glue string. Using the concat (||) feature, I was able to glom ‘&’ and ‘nbsp;’ together as the glue:

I wanted a quick way to query a logging table for today’s records. I figured there had to be some way to put a variable “today” into the query rather than put in the numbers for the current date. Voila — a query that retrieves records where the timestamp is greater than or equal to today:
select * from ossa_central_logging where action_ts >= cast(trunc(current_timestamp) as timestamp) order by action_ts desc;
I wanted to filter my result set to items where a column contained a value from another column — not that it was equal, but like. CONCAT allows me to do this:
nlA.clli_code LIKE CONCAT('%', CONCAT(nle.exchange_area_clli ,'%'))
Alternately, using ||
nlA.clli_code LIKE ('%' || nle.exchange_area_clli || '%')
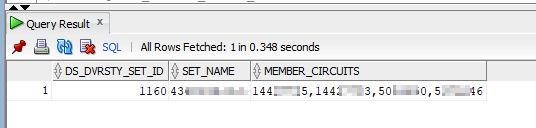
I needed to collapse multiple rows into a single row — the circuits within a diversity set are stored within the ds_dvrsty_set_circuit table as individual rows & the ds_dvrsty_set_id links the multiple rows. What I wanted was a set ID, set name, and the list of circuits within the set.
To accomplish this, I found LISTAGG which is a little bit like STUFF in MSSQL. This query produces a single row for each diversity set that contains the set ID, the set name, and a comma delimited list of set members.
SELECT
ds_dvrsty_set_circuit.ds_dvrsty_set_id,
(select ds_dvrsty_set.ds_dvrsty_set_nm from ds_dvrsty_set where ds_dvrsty_set_id = ds_dvrsty_set_circuit.ds_dvrsty_set_id) as set_name,
LISTAGG(ds_dvrsty_set_circuit.circuit_design_id, ',') WITHIN GROUP(ORDER BY ds_dvrsty_set_circuit.ds_dvrsty_set_id) AS member_circuits
FROM
ds_dvrsty_set_circuit
left outer join ds_dvrsty_set on ds_dvrsty_set.ds_dvrsty_set_id = ds_dvrsty_set_circuit.DS_DVRSTY_SET_ID
WHERE
ds_dvrsty_set_circuit.ds_dvrsty_set_id in (select distinct ds_dvrsty_set_id from ds_dvrsty_set_circuit where circuit_design_id in (14445678, 5078901) )
AND
ds_dvrsty_set.ds_dvrsty_set_nm like '43%'
GROUP BY
ds_dvrsty_set_circuit.ds_dvrsty_set_id
ORDER BY
ds_dvrsty_set_circuit.ds_dvrsty_set_id;
Voila — exactly what I needed. If the searched circuit design IDs appear in more than one set, there is a new row for each set ID.