Our database storage is sizable. To reduce the financial impact of storing so much data, we opted to use a compressed file system. This allows us to maintain, for example, 8TB of data in under 2TB of space. Unfortunately, the ZFS file system we use to compress our data is no longer “built in” with newer version of RedHat.
There are alternatives. BTRFS is a long-standing option, however it’s got reliability issues (we piloted BTRFS on one of the read only replicas, and the compression ratio is nowhere near as good — the 2TB of ZFS data filled the 10TB BTRFS disk even using the better compression option. And I/O was so slow there was a continual replication backlog). RedHat introduced Virtual Disk Optimizer to replace ZFS. In theory, it’s better since it also deduplicates data (e.g. if every one of us saved the same PPT presentation to the disk, only one copy would actually be stored). That’s great for email and file shares where a lot of people are likely to store the same information. Not so useful on a database server where there’s little to de-duplicate. It does, however, compress data … so we decided to try it out.
The results, unfortunately, are not spectacular. VDO does not allow you to do much customization of the compression. It’s on or off. I’ve found some people tweaking it up in unsupported ways, but the impetus behind trying VDO was that it’s supported by RedHat. Making unsupported changes to it defeats that purpose. And the compression that we’re seeing is far less than we get in ZFS. Our existing servers run between 4.5x and 6x compression

In VDO, however, we don’t even get a 2x compression factor. 11TB of information is stored in 8TB of space! That’s 1.4x
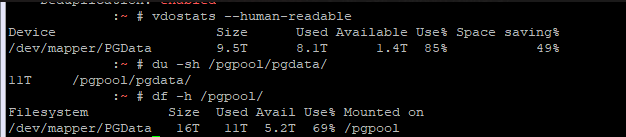
So, while we found the performance of VDO to be satisfactory and it’s really easy to use in newer RedHat releases … we’d have to increase our 20TB LUNs to 80TB to continue storing the data we store today. That seems like A Really Bad Idea(tm).
Seems like I’m going to have to sort out using OpenZFS on the new servers.