We have some servers that forward along data from various log files including their own /var/log/messages file … so I needed to filter out what is, to me, extraneous data. Good thing adding “NOT” to a query works!
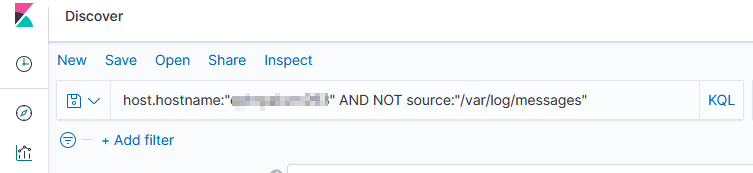
We have some servers that forward along data from various log files including their own /var/log/messages file … so I needed to filter out what is, to me, extraneous data. Good thing adding “NOT” to a query works!
Before upgrading to 8, you must be running at least version 7.17 … so I am first upgrading my ES7 to a new enough version that upgrading to ES8 is possible.
Not master eligible nodes:
a6b30865c82c.example.com
a6b30865c83c.example.com
Master eligible nodes:
a6b30865c81c.example.com
PUT _cluster/settings{ "persistent": { "cluster.routing.allocation.enable": "primaries" }}
POST _flush/synced
systemctl stop elasticsearch
b. Install the new RPM:
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.17.3-x86_64.rpm
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.17.3-x86_64.rpm.sha512
shasum -a 512 -c elasticsearch-7.17.3-x86_64.rpm.sha512
![]()
rpm -U elasticsearch-7.17.3-x86_64.rpm

c. Update configuration for new version
vi /usr/lib/tmpfiles.d/elasticsearch.conf
![]()
vi /etc/elasticsearch/elasticsearch.yml # Add the action.auto_create_index as required -- * for all, or you can restrict auto-creation to certain indices
![]()
d. Update unit file and start services
systemctl daemon-reload
systemctl enable elasticsearch
systemctl start elasticsearch.service

PUT _cluster/settings{"persistent": {"cluster.routing.allocation.enable": null }}
This isn’t something I will notice again now that I’ve got my heap space sorted … but when you are using Kibana to add index patterns, there’s nothing that waits until you’ve stopped typing for x seconds or implements a minimum characters before searching. So, after each character you type into the dialog, a search is performed against the ES server — here I wanted to create a pattern for logstash-* — which sent nine different search requests to my ES. And, if the server is operating reasonably, all of these searches would deliver a result set that Kibana essentially ignores as I’m tying more characters. But, in my case, the ES server fell over before I could even type logstash!

I was asked to look at a malfunctioning ElasticSearch server this week. It’s a lab sandbox, so not a huge deal … but still something they wanted online and functioning for some proof-of-concept testing. And, as a bonus, they’re willing to let us use their lab servers for our own sandboxing (IPv6 implementation, ELK upgrades). There were a handful of problems (it looks like the whole thing used to be a multi-node cluster but the second cluster node has vanished without any trace, the entire platform was re-IP’d, vm.max_map_count wasn’t set on the Docker server, and the logstash folder had a backup of a pipeline config in /path/to/logstash/pipeline/ … which still loads, so causes a continual stream of port-in-use exceptions). But the biggest problem was that any attempt at actually using the ElasticSearch server resulted in it falling over. Java crashed with an out of memory error because the heap space was exhausted. Now I’ve had really small sandboxes before — my first ES sandbox only had a gig of memory and was quite prone to this crash. But the lab server they’ve set up has 64GB of memory. So allocating a few gigs seemed like a quick solution.
The jvm.options file and jvm.options.d folder weren’t mounted into the container — they were the default files held within the container. Which seemed odd, and I made a mental note that it was something we’d need to either mount in or update again when the container gets updated. But no matter how much heap space I allocated, ES crashed.
I discovered that the Docker deployment set an ENV variable for ES_JAVA_OPTS — something which, per the ElasticSearch documentation, overrides all other JVM options. So no matter what I was putting into the jvm options file, the 256 meg set in the ENV was actually being used.
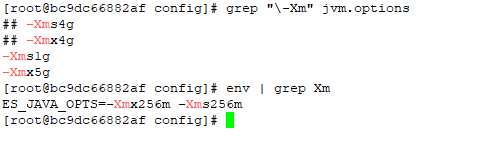
Luckily it’s not terribly difficult to modify the ENV’s within an existing container. You could, of course, redeploy the container with the new settings (and I’ll do that next time, since I’ve also got to get IPv6 enabled). But I wasn’t planning on making any other changes.
In all of these examples, the copy/paste text uses localhost and port 9200. Since some of my sandboxes don’t use the default port, some of the example outputs will use a different port. Obviously, use your hostname and port. And, if your ES instance requires authentication, add the “-u” option with the user (or user:password … but that’s not a good idea outside of sandboxes as the password is then stored to the shell history). If you are using https for the API endpoint, you may also need to add the “-k” option to establish an untrusted SSL connection (e.g. the CA isn’t trusted by your OS).
curl -k -u elastic https://localhost...
Listing All Indices
Use the following command to list all of the indices in the ES system:
curl http://localhost:9200/_cat/indices?v
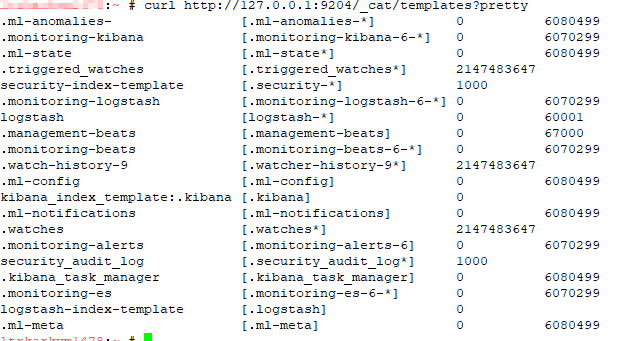
Listing All Templates
Use the following command to list all of the templates:
curl http://localhost:9200/_cat/templates?pretty
Explain Shard Allocation
I was asked to help get a ELK installation back into working order — one of the things I noticed is that all of the indices were yellow. The log file showed allocation errors. This command reported on the allocation decision that was being made. In the case I was looking at, the problem became immediately obvious — it was a single node system and 1 replica was defined. The explanation was that the shard could not be stored because it already existed in that place.
curl http://localhost:9200/_cluster/allocation/explain
If the maximum number of allocation retries has been exceeded, you can force ES to re-try allocation (as an example, a disk was full for an extended period of time but space has been cleared and everything should work now)
curl http://localhost:9200/_cluster/reroute?retry_failed=true
Set the Number of Replicas for a Single Index
Once I identified that the single node ELK instance had indices configured
curl -X PUT \
http://127.0.0.1:9200/logstash-2021.05.08/_settings \
-H 'cache-control: no-cache' \
-H 'content-type: application/json' \
-d '{"index" : {"number_of_replicas" : 0}}
'
Add an Alias to an Index
To add an alias to an existing index, use PUT /<indexname>/_alias/<aliasname> — e.g.
PUT /ljr-2022.07.05/_alias/ljr