Git log can be used to get a quick summary of the differences between two branches. The three dots between the branch names indicates you want a “symmetric difference”. That is the set of commits that are in the branch on the left or the branch on the right but not in both branches.
The –left-right option prefixes each commit with an ‘<’ or ‘>’ indicating which “side” has the commit. The –oneline option prints the abbreviated commit ID and the first line of the commit message.
Showing the differences between your local uat branch and the remote uat branch:
D:\git\gittest>git log –left-right –oneline origin/uat…uat
> 961f53a (uat) Merge branch ‘ossa-123’ into uat
> 803096b (origin/ossa-123, ossa-123) Added additional files
> cf9c419 Added initial code to branch
The top line is the most recent commit, the bottom line is the oldest commit that does not exist in both branches. I can see that the uat branch in my local repo is not missing anything from the remote (there are no commits with “<” indicating changes in the remote that do not exist in my local copy) but I have local changes which have not yet been pushed: two code commits plus the merge commit which incorporated the code commits to my local repo’s uat branch. The head of the local and remote ossa-123 branch are at the commit just prior to the merge, so on my local repo that branch has been fully merged into UAT and I just need to push uat up to the remote.
Additional options to enhance output:
–cherry-pick will omit any changes that represent the same changes in both branches (or –cherry-mark to mark those commits with an “=” flag)
–graph uses an ASCII chart to depict branch relationships.
* The three dots mean something different in git diff than in git log. In git diff, mean “what are the differences between the right-hand branch and the common ancestor shared by both the right and left-hand branches”.
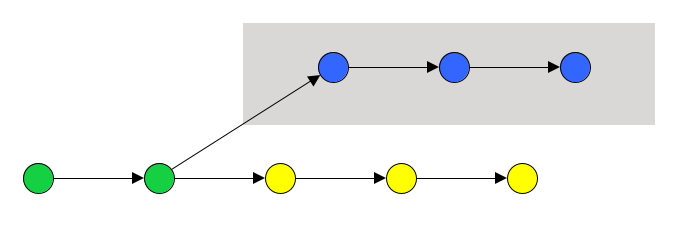
Two dots in git diff mean is the differences that are in the branch on the left or the branch on the right but not in both branches.
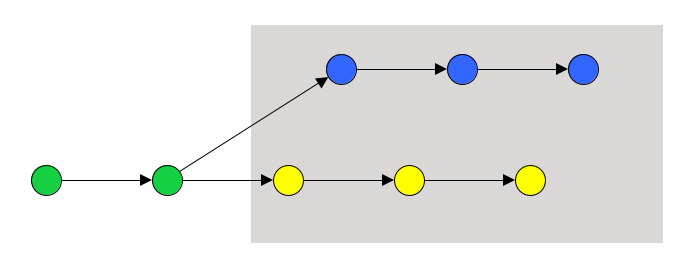
In git log, two dots displays only commits unique to the second branch. Since commits and differences are not exactly the same thing, two and three dots don’t exactly have the opposite meaning between diff and log. But the meaning is not logically consistent.