We are in the process of moving our k8s environment from CentOS 7 to RHEL 8.8 hosts — which means the version of pretty much everything involved is being updated. All of the pods that use images from an internal registry fail to load. At first, we were thinking DNS resolution … but the test pods we spun up all resolved names appropriately.
2023-09-13 13:48:34 [root@k8s ~/]# kubectl describe pod data-sync-app-deployment-78d58f7cd4-4mlsb -n streams
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 15m default-scheduler Successfully assigned kstreams/data-sync-app-deployment-78d58f7cd4-4mlsb to ltrkarkvm1593-uos
Normal Pulled 15m kubelet Container image "docker.elastic.co/beats/filebeat:7.9.1" already present on machine
Normal Created 15m kubelet Created container filebeat
Normal Started 15m kubelet Started container filebeat
Normal BackOff 15m (x3 over 15m) kubelet Back-off pulling image "imageregistry.example.net:5000/myapp/app_uat"
Warning Failed 15m (x3 over 15m) kubelet Error: ImagePullBackOff
Normal Pulling 14m (x3 over 15m) kubelet Pulling image "imageregistry.example.net:5000/myapp/app_uat"
Warning Failed 14m (x3 over 15m) kubelet Failed to pull image "imageregistry.example.net:5000/myapp/app_uat": rpc error: code = Unknown desc = failed to pull and unpack image "imageregistry.example.net:5000/myapp/app_uat:latest": failed to resolve reference "imageregistry.example.net:5000/npm/app_uat:latest": get registry endpoints: parse endpoint url: parse " http://imageregistry.example.net:5000": first path segment in URL cannot contain colon
Warning Failed 14m (x3 over 15m) kubelet Error: ErrImagePull
Warning DNSConfigForming 31s (x73 over 15m) kubelet Search Line limits were exceeded, some search paths have been omitted, the applied search line is: kstreams.s vc.cluster.local svc.cluster.local cluster.local example.net sub1.example.net sub2.example.net
I have found “first path segment in URL cannot contain colon” in reference to Go — and some previous versions at that. There were all sorts of suggestions for working around the issue — escaping the colon, starting with “//”, adding single or double quotes around the string, downgrading to a version of Go not impacted by the problem. Nothing worked.
A few hours with no progress, I thought some time investigating “how can I work around this?” was in order. Kubernetes is using containerd … so it should be feasible to pre-stage the image in containerd and then set our imagePullPolicy values to IfNotPresent or Never
To pre-seed the images in containerd so that they are available for kubernetes run:
ctr -n=k8s.io image pull -u $REGISTRYUSER:$REGISTRYPASSWORD --plain-http imageregistry.example.net:5000/myapp/app_uat:latest
This must be run on every k8s worker in the environment — if a pod tries to spin up on server2 but you’ve only seeded the image file on server1 … the pod will fail to load. We need to update this staged image every time we make changes to the application. Better than not using the new servers, so that’ll just be the process for a while.
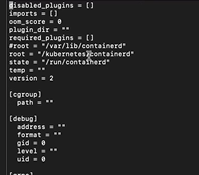
Ultimately, the problem ended up being that a few of the workers had a leading space in the TOML file for the repo — how that got there, I have no idea. But once there was no longer extraneous white-space, we could deploy the pods without issue. Now that it’s working “as designed”, we deleted the pre-seeded image using:
ctr -n=k8s.io images rm ImageNameHere